Amazon Bedrock Adiciona Filtragem de Metadados para Memória de Longo Prazo de Agentes de IA para Melhorar a Precisão de Recuperação
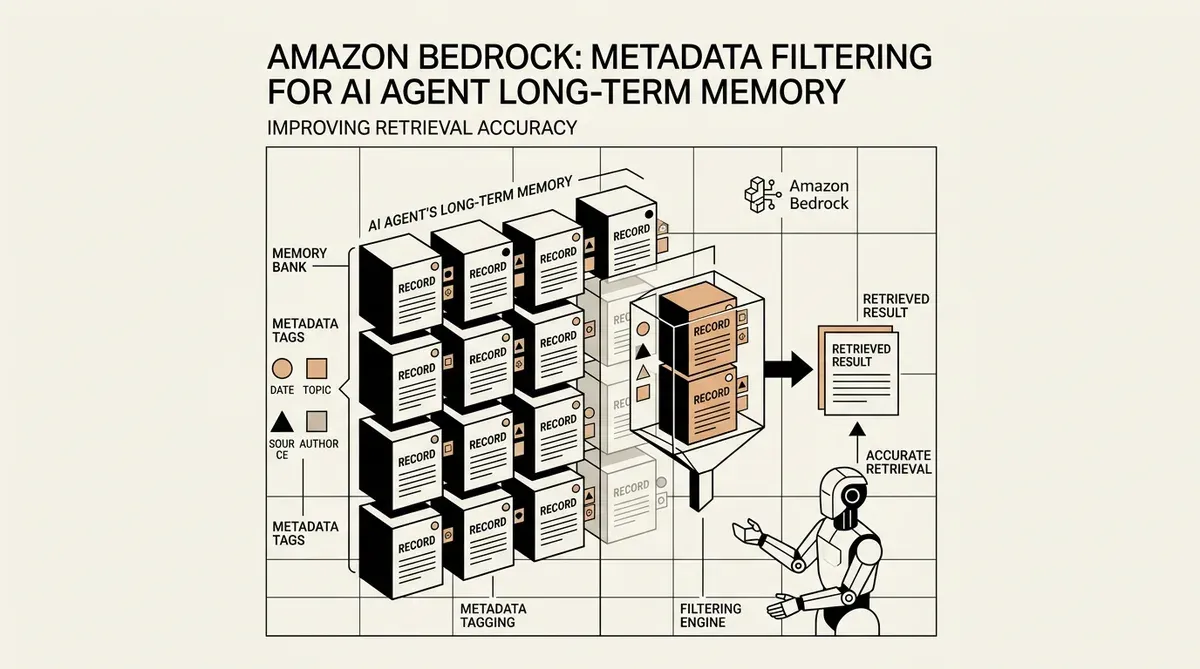
O Amazon Bedrock atualizou seu recurso AgentCore Memory para suportar a filtragem de metadados para registros de memória de longo prazo, uma iniciativa projetada para melhorar a forma como os agentes de IA gerenciam e recuperam dados históricos. Esta atualização permite que os desenvolvedores marquem e filtrem memórias usando atributos estruturados, indo além da simples busca semântica para fornecer um contexto mais preciso para agentes autônomos. Ao integrar a metadata filtering for AI agent long-term memory, a plataforma visa reduzir o ruído nos loops de raciocínio que frequentemente ocorre quando os agentes recuperam informações irrelevantes de interações passadas.
A nova funcionalidade, anunciada esta semana, permite a definição de até dez chaves indexadas por recurso de memória. Essas chaves suportam vários tipos de dados, incluindo STRING, NUMBER e STRING_LIST, permitindo uma organização granular dos dados armazenados. Os desenvolvedores agora podem implementar uma lógica que filtra os resultados de recuperação com base em operadores específicos, garantindo que um agente acesse apenas memórias relevantes para um ID de usuário, intervalo de datas ou nível de prioridade específico. Essa abordagem estruturada visa resolver o problema de "perda no meio" (lost in the middle), onde os LLMs têm dificuldade em processar grandes volumes de texto recuperado.
Impacto Estratégico da Metadata Filtering for AI Agent Long-Term Memory
Para líderes empresariais, a adição da metadata filtering for AI agent long-term memory representa uma mudança em direção a fluxos de trabalho agênticos mais confiáveis. A busca semântica padrão frequentemente recupera informações que são matematicamente semelhantes, mas contextualmente inadequadas. Ao permitir que os agentes filtrem por atributos rígidos (como um código de projeto específico ou uma jurisdição legal), as empresas podem impor limites mais rigorosos sobre quais dados uma IA considera durante seu processo de tomada de decisão. Isso reduz o risco de alucinações causadas por registros históricos desatualizados ou conflitantes.
A Amazon também simplificou o processo de implementação ao permitir que os metadados sejam anexados de duas maneiras. Eles podem ser atribuídos manualmente pelos desenvolvedores ou extraídos automaticamente pelo modelo de linguagem de grande escala subjacente. Essa flexibilidade é fundamental para escalar implantações de agentes onde a marcação manual de cada interação não é viável. A capacidade de categorizar automaticamente as memórias com base no conteúdo da conversa garante que a memória de longo prazo permaneça organizada sem intervenção humana constante.
A introdução desses atributos estruturados alinha-se com a tendência mais ampla da indústria de migrar de chatbots simples para agentes autônomos sofisticados. À medida que esses sistemas assumem tarefas complexas de várias etapas, a eficiência da recuperação de memória torna-se um gargalo de desempenho. O foco da Amazon em chaves indexadas e filtragem baseada em operadores fornece a infraestrutura técnica necessária para que os agentes mantenham alta precisão durante longos períodos de operação. Esta atualização está disponível para usuários do Amazon Bedrock AgentCore Memory desde maio de 2026.
Embora nos esforcemos pela precisão, o bytevyte pode cometer erros. Os usuários são aconselhados a verificar todas as informações de forma independente. Não aceitamos qualquer responsabilidade por erros ou omissões.
Sources
Amazon Bedrock Adds Metadata Filtering for AI Agent Long-Term Memory
Related Articles
- AWS Lança Amazon Bedrock AgentCore na América do Sul para Impulsionar a Implantação Regional de IA
- AWS Agent Registry é lançado para centralizar a governança de IA
- AWS Introduces Automated Optimization Tools for Amazon Bedrock AI Agents
✔Human Verified