Amazon Bedrock aggiunge il filtraggio dei metadati per la memoria a lungo termine degli agenti AI per migliorare l'accuratezza del recupero
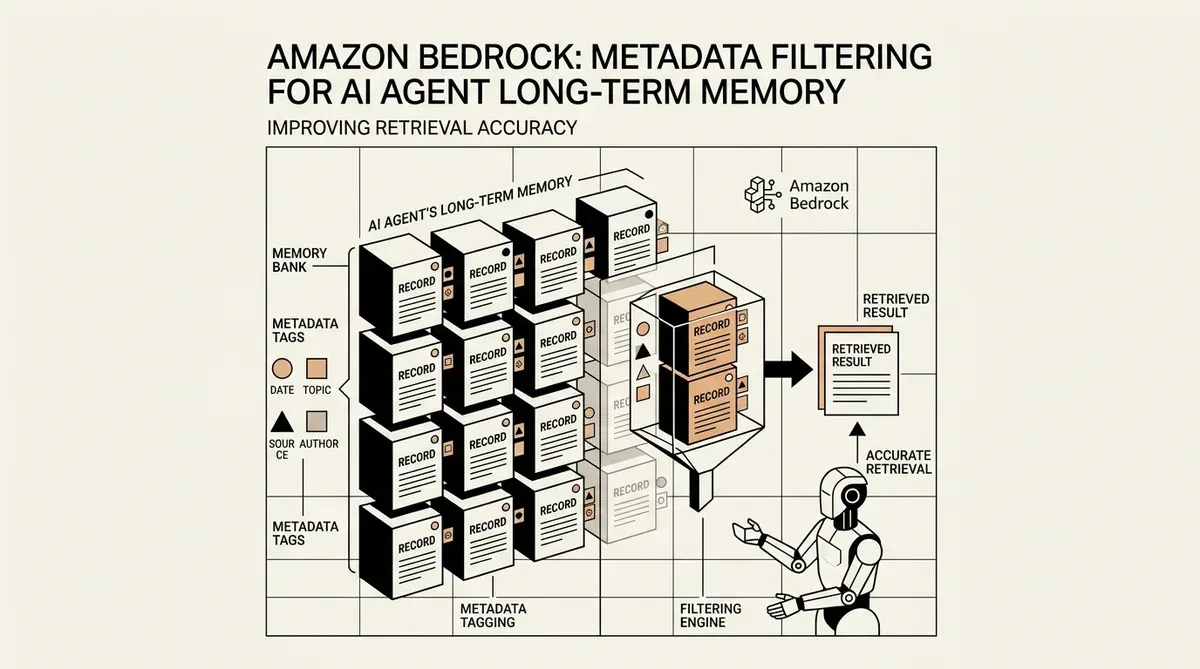
Amazon Bedrock ha aggiornato la sua funzione AgentCore Memory per supportare il filtraggio dei metadati per i record di memoria a lungo termine, una mossa progettata per migliorare il modo in cui gli agenti AI gestiscono e recuperano i dati storici. Questo aggiornamento consente agli sviluppatori di taggare e filtrare le memorie utilizzando attributi strutturati, andando oltre la semplice ricerca semantica per fornire un contesto più preciso agli agenti autonomi. Integrando il metadata filtering for AI agent long-term memory, la piattaforma mira a ridurre il rumore nei cicli di ragionamento che spesso si verifica quando gli agenti recuperano informazioni irrilevanti da interazioni passate.
La nuova funzionalità, annunciata questa settimana, consente la definizione di un massimo di dieci chiavi indicizzate per risorsa di memoria. Queste chiavi supportano vari tipi di dati, tra cui STRING, NUMBER e STRING_LIST, consentendo un'organizzazione granulare dei dati archiviati. Gli sviluppatori possono ora implementare una logica che filtra i risultati del recupero in base a operatori specifici, garantendo che un agente acceda solo alle memorie pertinenti a un particolare ID utente, intervallo di date o livello di priorità. Questo approccio strutturato è destinato a risolvere il problema del "lost in the middle", in cui gli LLM faticano a elaborare grandi volumi di testo recuperato.
Impatto strategico del metadata filtering for AI agent long-term memory
Per i leader aziendali, l'aggiunta del metadata filtering for AI agent long-term memory rappresenta un passaggio verso workflow agentici più affidabili. La ricerca semantica standard spesso recupera informazioni matematicamente simili ma contestualmente inappropriate. Consentendo agli agenti di filtrare per attributi rigidi (come un codice progetto specifico o una giurisdizione legale), le aziende possono imporre confini più severi su quali dati un'IA considera durante il suo processo decisionale. Ciò riduce il rischio di allucinazioni causate da record storici obsoleti o contrastanti.
Amazon ha inoltre semplificato il processo di implementazione consentendo l'allegatamento dei metadati in due modi. Possono essere assegnati manualmente dagli sviluppatori o estratti automaticamente dal modello linguistico di grandi dimensioni sottostante. Questa flessibilità è fondamentale per scalare le implementazioni degli agenti dove il tagging manuale di ogni interazione non è fattibile. La capacità di categorizzare automaticamente le memorie in base al contenuto della conversazione assicura che la memoria a lungo termine rimanga organizzata senza un costante intervento umano.
L'introduzione di questi attributi strutturati si allinea con la tendenza più ampia del settore di passare da semplici chatbot a sofisticati agenti autonomi. Man mano che questi sistemi assumono compiti multi-fase più complessi, l'efficienza del recupero della loro memoria diventa un collo di bottiglia per le prestazioni. Il focus di Amazon sulle chiavi indicizzate e sul filtraggio basato su operatori fornisce l'infrastruttura tecnica necessaria affinché gli agenti mantengano un'elevata accuratezza su periodi di funzionamento prolungati. Questo aggiornamento è attualmente disponibile per gli utenti di Amazon Bedrock AgentCore Memory a partire da maggio 2026.
Sebbene ci sforziamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Sources
Amazon Bedrock Adds Metadata Filtering for AI Agent Long-Term Memory
Related Articles
- OpenAI GPT-5.5 e Managed Agents arrivano su Amazon Bedrock
- AWS lancia Amazon Bedrock AgentCore in Sud America per potenziare l'implementazione regionale dell'IA
- AWS introduce strumenti di ottimizzazione automatizzata per gli agenti AI di Amazon Bedrock
✔Human Verified