Amazon Bedrock añade filtrado por metadatos para la memoria a largo plazo de agentes de IA para mejorar la precisión de recuperación
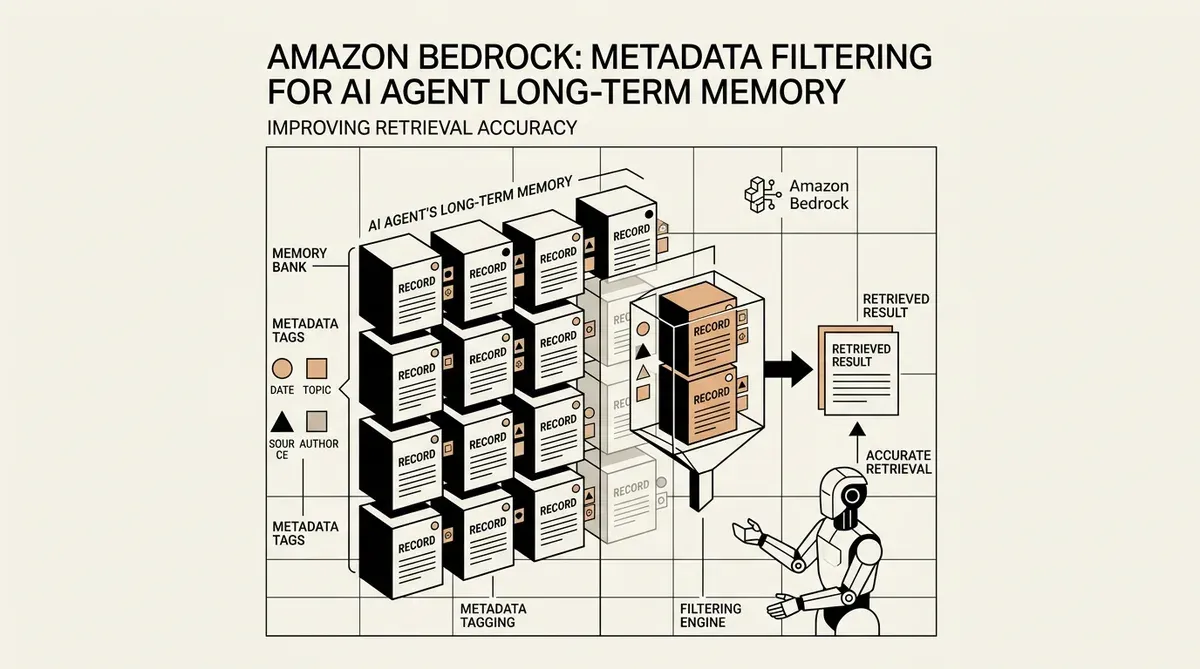
Amazon Bedrock ha actualizado su función AgentCore Memory para admitir el filtrado por metadatos en los registros de memoria a largo plazo, un movimiento diseñado para mejorar la forma en que los agentes de IA gestionan y recuperan datos históricos. Esta actualización permite a los desarrolladores etiquetar y filtrar memorias utilizando atributos estructurados, yendo más allá de la simple búsqueda semántica para proporcionar un contexto más preciso a los agentes autónomos. Al integrar el metadata filtering for AI agent long-term memory, la plataforma pretende reducir el ruido en los bucles de razonamiento que suele producirse cuando los agentes recuperan información irrelevante de interacciones pasadas.
La nueva capacidad, anunciada esta semana, permite la definición de hasta diez claves indexadas por recurso de memoria. Estas claves admiten varios tipos de datos, incluidos STRING, NUMBER y STRING_LIST, lo que permite una organización granular de los datos almacenados. Los desarrolladores ahora pueden implementar una lógica que filtre los resultados de recuperación basándose en operadores específicos, garantizando que un agente solo acceda a memorias relevantes para un ID de usuario, rango de fechas o nivel de prioridad particular. Este enfoque estructurado está destinado a resolver el problema de "pérdida en el medio" (lost in the middle), donde los LLM tienen dificultades para procesar grandes volúmenes de texto recuperado.
Impacto estratégico del metadata filtering for AI agent long-term memory
Para los líderes empresariales, la adición del metadata filtering for AI agent long-term memory supone un cambio hacia flujos de trabajo agénticos más fiables. La búsqueda semántica estándar a menudo recupera información que es matemáticamente similar pero contextualmente inapropiada. Al permitir que los agentes filtren por atributos rígidos (como un código de proyecto específico o una jurisdicción legal), las empresas pueden imponer límites más estrictos sobre qué datos considera una IA durante su proceso de toma de decisiones. Esto reduce el riesgo de alucinaciones causadas por registros históricos obsoletos o contradictorios.
Amazon también ha simplificado el proceso de implementación al permitir que los metadatos se adjunten de dos maneras. Pueden ser asignados manualmente por los desarrolladores o extraídos automáticamente por el modelo de lenguaje de gran tamaño subyacente. Esta flexibilidad es clave para escalar despliegues de agentes donde el etiquetado manual de cada interacción no es factible. La capacidad de categorizar automáticamente las memorias basándose en el contenido de la conversación garantiza que la memoria a largo plazo permanezca organizada sin intervención humana constante.
La introducción de estos atributos estructurados se alinea con la tendencia general de la industria de pasar de simples chatbots a sofisticados agentes autónomos. A medida que estos sistemas asumen tareas más complejas y de varios pasos, la eficiencia de su recuperación de memoria se convierte en un cuello de botella para el rendimiento. El enfoque de Amazon en claves indexadas y filtrado basado en operadores proporciona la infraestructura técnica necesaria para que los agentes mantengan una alta precisión durante periodos prolongados de operación. Esta actualización está disponible actualmente para los usuarios de Amazon Bedrock AgentCore Memory a partir de mayo de 2026.
Aunque nos esforzamos por la exactitud, bytevyte puede cometer errores. Se aconseja a los usuarios verificar toda la información de forma independiente. No aceptamos ninguna responsabilidad por errores u omisiones.
Sources
Amazon Bedrock Adds Metadata Filtering for AI Agent Long-Term Memory
Related Articles
- AWS lanza Amazon Bedrock AgentCore en Sudamérica para impulsar el despliegue regional de IA
- AWS introduce herramientas de optimización automatizada para agentes de IA de Amazon Bedrock
- AWS Agent Registry se lanza para centralizar la gobernanza de la IA
✔Human Verified