Amazon Bedrock führt Metadaten-Filterung für das Langzeitgedächtnis von KI-Agenten ein, um die Abrufgenauigkeit zu verbessern
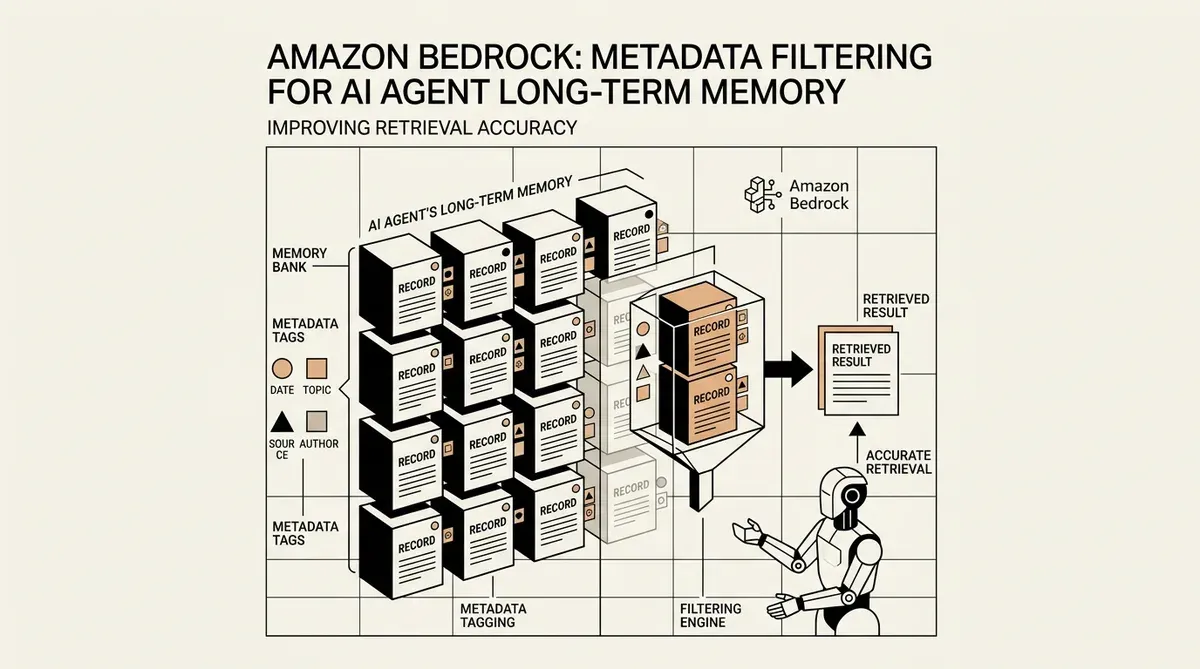
Amazon Bedrock hat seine AgentCore Memory-Funktion aktualisiert, um die Metadaten-Filterung für Langzeitgedächtnis-Einträge zu unterstützen – ein Schritt, der darauf abzielt, die Verwaltung und den Abruf historischer Daten durch KI-Agenten zu verbessern. Dieses Update ermöglicht es Entwicklern, Erinnerungen mithilfe strukturierter Attribute zu taggen und zu filtern, was über die einfache semantische Suche hinausgeht, um präziseren Kontext für autonome Agenten bereitzustellen. Durch die Integration von Metadaten-Filterung für das Langzeitgedächtnis von KI-Agenten möchte die Plattform das Rauschen in Reasoning-Loops reduzieren, das häufig auftritt, wenn Agenten irrelevante Informationen aus vergangenen Interaktionen abrufen.
Die neue Funktion, die diese Woche angekündigt wurde, ermöglicht die Definition von bis zu zehn indizierten Schlüsseln pro Memory-Ressource. Diese Schlüssel unterstützen verschiedene Datentypen, einschließlich STRING, NUMBER und STRING_LIST, was eine granulare Organisation gespeicherter Daten erlaubt. Entwickler können nun Logiken implementieren, die Abrufergebnisse basierend auf spezifischen Operatoren filtern. So wird sichergestellt, dass ein Agent nur auf Erinnerungen zugreift, die für eine bestimmte User-ID, einen Datumsbereich oder eine Prioritätsstufe relevant sind. Dieser strukturierte Ansatz soll das „Lost in the Middle“-Problem lösen, bei dem LLMs Schwierigkeiten haben, große Mengen an abgerufenem Text zu verarbeiten.
Strategische Auswirkungen der Metadaten-Filterung für das Langzeitgedächtnis von KI-Agenten
Für Unternehmensleiter bedeutet die Einführung der Metadaten-Filterung für das Langzeitgedächtnis von KI-Agenten einen Wandel hin zu zuverlässigeren agentischen Workflows. Die standardmäßige semantische Suche liefert oft Informationen, die mathematisch ähnlich, aber kontextuell unpassend sind. Indem Agenten nach harten Attributen filtern können (wie etwa einem spezifischen Projektcode oder einer Rechtsordnung), können Unternehmen strengere Grenzen setzen, welche Daten eine KI bei ihrer Entscheidungsfindung berücksichtigt. Dies verringert das Risiko von Halluzinationen, die durch veraltete oder widersprüchliche historische Aufzeichnungen verursacht werden.
Amazon hat zudem den Implementierungsprozess vereinfacht, indem Metadaten auf zwei Arten zugewiesen werden können. Sie können manuell von Entwicklern vergeben oder automatisch durch das zugrunde liegende Large Language Model extrahiert werden. Diese Flexibilität ist entscheidend für die Skalierung von Agenten-Deployments, bei denen ein manuelles Tagging jeder Interaktion nicht machbar ist. Die Fähigkeit, Erinnerungen basierend auf dem Gesprächsinhalt automatisch zu kategorisieren, stellt sicher, dass das Langzeitgedächtnis ohne ständiges menschliches Eingreifen organisiert bleibt.
Die Einführung dieser strukturierten Attribute steht im Einklang mit dem allgemeinen Branchentrend, sich von einfachen Chatbots hin zu hochentwickelten autonomen Agenten zu bewegen. Da diese Systeme immer komplexere, mehrstufige Aufgaben übernehmen, wird die Effizienz ihres Speicherabrufs zu einem Leistungsengpass. Amazons Fokus auf indizierte Schlüssel und operatorbasierte Filterung bietet die technische Infrastruktur, die erforderlich ist, damit Agenten über längere Betriebszeiträume eine hohe Genauigkeit beibehalten. Dieses Update ist für Nutzer von Amazon Bedrock AgentCore Memory ab Mai 2026 verfügbar.
Obwohl wir um Genauigkeit bemüht sind, kann bytevyte Fehler machen. Nutzern wird empfohlen, alle Informationen unabhängig zu überprüfen. Wir übernehmen keine Haftung für Fehler oder Auslassungen.
Sources
Amazon Bedrock Adds Metadata Filtering for AI Agent Long-Term Memory
Related Articles
- OpenAI GPT-5.5 und Managed Agents kommen auf Amazon Bedrock
- AWS führt automatisierte Optimierungstools für Amazon Bedrock AI Agents ein
- AWS führt Amazon Bedrock AgentCore in Südamerika ein, um den regionalen KI-Einsatz zu fördern
✔Human Verified