AWS Estreia Instâncias Amazon EC2 P6-B300 com GPUs NVIDIA Blackwell Ultra
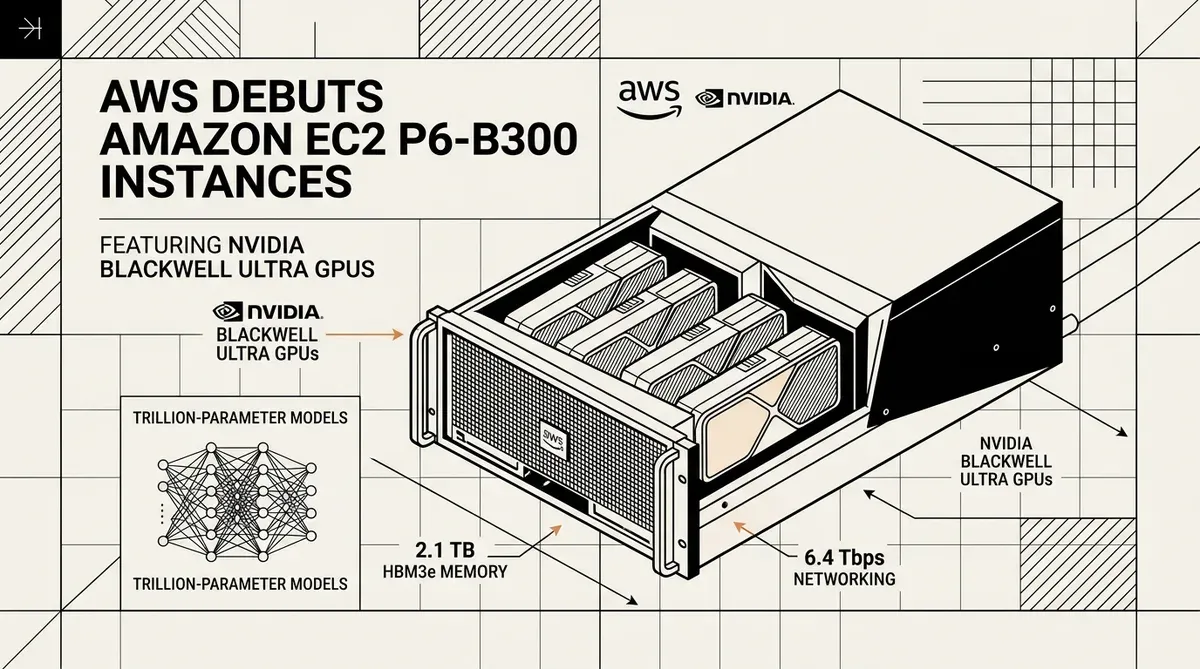
Amazon Web Services lançou as instâncias Amazon EC2 P6-B300, marcando uma atualização significativa na infraestrutura de nuvem para o treinamento de modelos de fundação com trilhões de parâmetros. Estas novas instâncias, equipadas com NVIDIA Blackwell Ultra GPUs, já estão disponíveis nas regiões US East (N. Virginia) e US West (Oregon) desde maio de 2026. O lançamento visa tomadores de decisão corporativos e pesquisadores de IA que exigem escala computacional massiva para a próxima geração de grandes modelos de linguagem.
A plataforma Amazon EC2 P6-B300 integra oito GPUs NVIDIA Blackwell Ultra por instância, proporcionando um salto substancial no desempenho em relação às gerações anteriores. Cada instância possui 2,1 TB de memória de GPU de alta largura de banda (HBM3e), o que representa um aumento de 50% em comparação com os modelos P6-B200. Essa expansão de memória permite que pesos de modelos maiores sejam mantidos localmente na GPU, reduzindo a necessidade de trocas frequentes de dados e acelerando o treinamento de redes neurais complexas.
Especificações Técnicas e Desempenho de Rede
Além do poder bruto da GPU, as instâncias Amazon EC2 P6-B300 introduzem melhorias importantes na movimentação de dados e na memória do sistema. Construídas sobre o AWS Nitro System, estas instâncias descarregam funções de E/S e segurança para hardware dedicado, garantindo que os recursos primários de computação permaneçam focados em cargas de trabalho de IA. A memória do sistema foi escalada para 4.096 GiB para suportar a natureza intensiva de dados dos pipelines de IA modernos.
A taxa de transferência de rede teve sua capacidade dobrada através da implementação do EFAv4 (Elastic Fabric Adapter). As instâncias entregam 6,4 Tbps de largura de banda de rede, juntamente com 300 Gbps de taxa de transferência dedicada de ENA (Elastic Network Adapter). Essa interconexão de alta velocidade é essencial para o treinamento distribuído, onde milhares de GPUs devem se comunicar com latência mínima para sincronizar os gradientes do modelo. A integração do PCIe Gen6 apoia ainda mais essa taxa de transferência, dobrando as taxas internas de transferência de dados entre os componentes do sistema.
- 8x GPUs NVIDIA Blackwell Ultra por instância.
- 2.144 GB de memória de GPU HBM3e.
- 6,4 Tbps de largura de banda de rede EFAv4.
- 4.096 GiB de memória do sistema.
- Integração PCIe Gen6 para transferência de dados aprimorada.
Implicações Estratégicas para o Desenvolvimento de IA
A introdução das instâncias Amazon EC2 P6-B300 reflete a intensificação da corrida para fornecer a infraestrutura necessária para modelos de IA de "fronteira". Ao oferecer 1,5x mais TFLOPS de GPU em precisão FP4 do que seus antecessores, a AWS está se posicionando como o principal destino para organizações que desenvolvem modelos de trilhões de parâmetros. A transição para a memória HBM3e e a conectividade PCIe Gen6 aborda os principais gargalos no escalonamento de IA: capacidade de memória e velocidade de interconexão.
Para CTOs e estrategistas de IA, este lançamento oferece um caminho claro para escalar operações sem a necessidade imediata de investimento em hardware local. A disponibilidade dessas instâncias nas principais regiões da AWS permite a implantação imediata de clusters de alto desempenho. À medida que cresce a demanda por IA multimodal e modelos de raciocínio sofisticados, a capacidade de acessar o silício Blackwell Ultra via nuvem é uma vantagem competitiva fundamental para empresas que buscam minimizar o tempo de colocação no mercado para novos produtos de IA. Essa flexibilidade é particularmente útil para startups que precisam de picos de capacidade computacional durante as fases finais de treinamento do modelo.
A AWS confirmou que o tamanho p6-b300.48xlarge é a configuração principal para estas instâncias. As organizações podem agora começar a provisionar esses recursos através do Console de Gerenciamento da AWS ou da Interface de Linha de Comando para apoiar seus projetos de aprendizado de máquina mais exigentes. A empresa indicou que estas instâncias são otimizadas para as arquiteturas Ultraserver mais recentes, que podem agregar até 13.320 GB de memória de GPU em um único cluster para tarefas massivas de processamento paralelo.
Embora busquemos a precisão, o bytevyte pode cometer erros. Os usuários são aconselhados a verificar todas as informações de forma independente. Não aceitamos qualquer responsabilidade por erros ou omissões.
Related Articles
- AWS Integra GPUs NVIDIA Blackwell ao SageMaker com Novas Instâncias G7e
- Amazon Bedrock integra OpenAI GPT OSS e NVIDIA Nemotron para diversificar opções de IA empresarial
- AWS Lança Amazon Bedrock AgentCore na América do Sul para Impulsionar a Implantação Regional de IA
✔Human Verified