AWS estrena las instancias Amazon EC2 P6-B300 con GPUs NVIDIA Blackwell Ultra
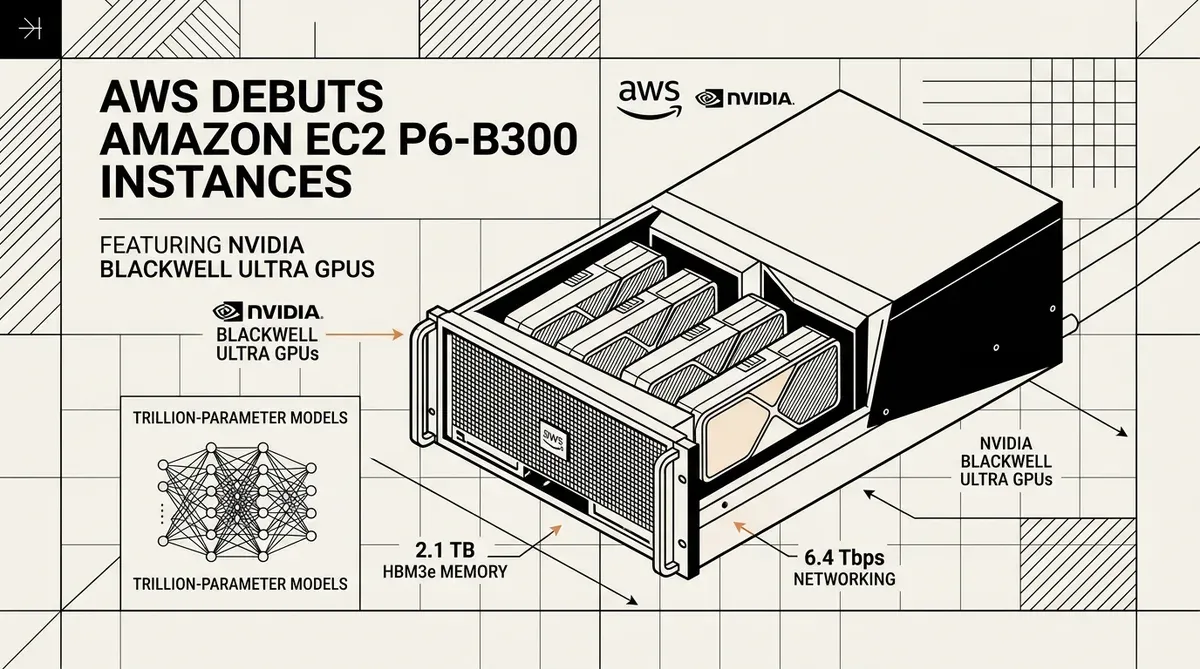
Amazon Web Services ha lanzado las instancias Amazon EC2 P6-B300, lo que supone una mejora significativa en la infraestructura de la nube para el entrenamiento de modelos fundacionales de billones de parámetros. Estas nuevas instancias, impulsadas por NVIDIA Blackwell Ultra GPUs, ya están disponibles en las regiones de US East (N. Virginia) y US West (Oregon) a partir de mayo de 2026. El lanzamiento está dirigido a los responsables de la toma de decisiones empresariales y a los investigadores de IA que requieren una escala computacional masiva para la próxima generación de modelos de lenguaje de gran tamaño.
La plataforma Amazon EC2 P6-B300 integra ocho NVIDIA Blackwell Ultra GPUs por instancia, lo que proporciona un salto sustancial en el rendimiento con respecto a las generaciones anteriores. Cada instancia cuenta con 2,1 TB de memoria GPU de gran ancho de banda (HBM3e), lo que supone un aumento del 50% en comparación con los modelos P6-B200. Esta expansión de memoria permite que los pesos de modelos más grandes se mantengan localmente en la GPU, reduciendo la necesidad de intercambios de datos frecuentes y acelerando el entrenamiento de redes neuronales complejas.
Especificaciones técnicas y rendimiento de red
Más allá de la potencia bruta de la GPU, las instancias Amazon EC2 P6-B300 introducen mejoras importantes en el movimiento de datos y la memoria del sistema. Basadas en el AWS Nitro System, estas instancias delegan las funciones de E/S y seguridad a hardware dedicado, garantizando que los recursos de cómputo primarios permanezcan enfocados en las cargas de trabajo de IA. La memoria del sistema se ha escalado a 4.096 GiB para soportar la naturaleza intensiva en datos de los canales de IA modernos.
El rendimiento de red experimenta una duplicación de su capacidad mediante la implementación de EFAv4 (Elastic Fabric Adapter). Las instancias ofrecen 6,4 Tbps de ancho de banda de red, junto con 300 Gbps de rendimiento dedicado de ENA (Elastic Network Adapter). Esta interconexión de alta velocidad es esencial para el entrenamiento distribuido, donde miles de GPUs deben comunicarse con una latencia mínima para sincronizar los gradientes del modelo. La integración de PCIe Gen6 respalda aún más este rendimiento al duplicar las tasas de transferencia de datos internas entre los componentes del sistema.
- 8x NVIDIA Blackwell Ultra GPUs por instancia.
- 2.144 GB de memoria GPU HBM3e.
- 6,4 Tbps de ancho de banda de red EFAv4.
- 4.096 GiB de memoria del sistema.
- Integración de PCIe Gen6 para una transferencia de datos mejorada.
Implicaciones estratégicas para el desarrollo de IA
La introducción de las instancias Amazon EC2 P6-B300 refleja la intensificación de la carrera por proporcionar la infraestructura necesaria para los modelos de IA de "frontera". Al ofrecer 1,5 veces más TFLOPS de GPU en precisión FP4 que sus predecesoras, AWS se posiciona como el destino principal para las organizaciones que desarrollan modelos de billones de parámetros. La transición a la memoria HBM3e y la conectividad PCIe Gen6 aborda los principales cuellos de botella en el escalado de la IA: la capacidad de memoria y la velocidad de interconexión.
Para los CTOs y estrategas de IA, este lanzamiento proporciona un camino claro para escalar operaciones sin la necesidad inmediata de inversión en hardware local. La disponibilidad de estas instancias en las principales regiones de AWS permite el despliegue inmediato de clústeres de alto rendimiento. A medida que crece la demanda de IA multimodal y modelos de razonamiento sofisticados, la capacidad de acceder al silicio Blackwell Ultra a través de la nube es una ventaja competitiva clave para las empresas que buscan minimizar el tiempo de comercialización de nuevos productos de IA. Esta flexibilidad es particularmente útil para las startups que necesitan aumentar su capacidad de cómputo durante las fases finales de entrenamiento de modelos.
AWS confirmó que el tamaño p6-b300.48xlarge es la configuración principal para estas instancias. Las organizaciones pueden comenzar ahora a aprovisionar estos recursos a través de la AWS Management Console o la Command Line Interface para respaldar sus proyectos de aprendizaje automático más exigentes. La compañía ha indicado que estas instancias están optimizadas para las últimas arquitecturas Ultraserver, que pueden agregar hasta 13.320 GB de memoria GPU en un solo clúster para tareas de procesamiento paralelo masivo.
Aunque nos esforzamos por la exactitud, bytevyte puede cometer errores. Se aconseja a los usuarios verificar toda la información de forma independiente. No aceptamos ninguna responsabilidad por errores u omisiones.
Related Articles
- AWS integra las GPUs NVIDIA Blackwell en SageMaker con las nuevas instancias G7e
- Amazon Bedrock integra OpenAI GPT OSS y NVIDIA Nemotron para diversificar las opciones de IA empresarial
- Intel y Google Cloud impulsan el rendimiento de la IA con Xeon 6 y silicio personalizado
✔Human Verified