AWS führt Amazon EC2 P6-B300 Instanzen mit NVIDIA Blackwell Ultra GPUs ein
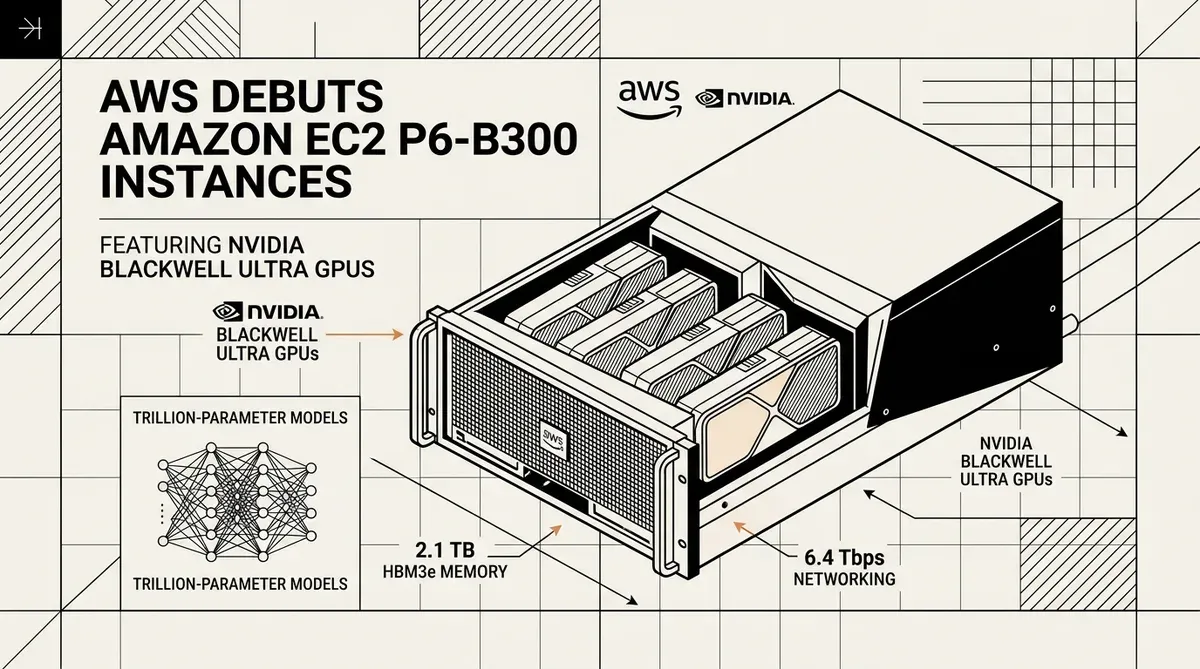
Amazon Web Services hat die Amazon EC2 P6-B300 Instanzen eingeführt und damit ein bedeutendes Upgrade der Cloud-Infrastruktur für das Training von Foundation-Modellen mit Billionen von Parametern vollzogen. Diese neuen Instanzen, die von NVIDIA Blackwell Ultra GPUs angetrieben werden, sind seit Mai 2026 in den Regionen US East (N. Virginia) und US West (Oregon) verfügbar. Das Release richtet sich an Entscheidungsträger in Unternehmen und AI-Forscher, die für die nächste Generation großer Sprachmodelle massive Rechenkapazitäten benötigen.
Die Amazon EC2 P6-B300 Plattform integriert acht NVIDIA Blackwell Ultra GPUs pro Instanz und bietet damit einen erheblichen Leistungssprung gegenüber früheren Generationen. Jede Instanz verfügt über 2,1 TB High-Bandwidth GPU-Speicher (HBM3e), was einer Steigerung von 50 % im Vergleich zu den P6-B200 Modellen entspricht. Diese Speichererweiterung ermöglicht es, größere Modellgewichte lokal auf der GPU zu halten, was die Notwendigkeit häufiger Datenaustausche reduziert und das Training komplexer neuronaler Netze beschleunigt.
Technische Spezifikationen und Networking-Performance
Über die reine GPU-Leistung hinaus führen die Amazon EC2 P6-B300 Instanzen umfassende Verbesserungen beim Datentransfer und beim Systemarbeitsspeicher ein. Basierend auf dem AWS Nitro System lagern diese Instanzen I/O- und Sicherheitsfunktionen auf dedizierte Hardware aus, um sicherzustellen, dass die primären Rechenressourcen auf AI-Workloads fokussiert bleiben. Der Systemarbeitsspeicher wurde auf 4.096 GiB skaliert, um der datenintensiven Natur moderner AI-Pipelines gerecht zu werden.
Der Netzwerkdurchsatz erfährt durch die Implementierung von EFAv4 (Elastic Fabric Adapter) eine Verdoppelung der Kapazität. Die Instanzen liefern eine Netzwerkbandbreite von 6,4 Tbps sowie einen dedizierten ENA (Elastic Network Adapter) Durchsatz von 300 Gbps. Dieser Hochgeschwindigkeits-Interconnect ist essenziell für verteiltes Training, bei dem Tausende von GPUs mit minimaler Latenz kommunizieren müssen, um Modellgradienten zu synchronisieren. Die Integration von PCIe Gen6 unterstützt diesen Durchsatz zusätzlich, indem sie die internen Datentransferraten zwischen den Systemkomponenten verdoppelt.
- 8x NVIDIA Blackwell Ultra GPUs pro Instanz.
- 2.144 GB HBM3e GPU-Speicher.
- 6,4 Tbps EFAv4 Netzwerkbandbreite.
- 4.096 GiB Systemarbeitsspeicher.
- PCIe Gen6 Integration für verbesserten Datentransfer.
Strategische Auswirkungen für die AI-Entwicklung
Die Einführung der Amazon EC2 P6-B300 Instanzen spiegelt den intensiver werdenden Wettlauf um die Bereitstellung der notwendigen Infrastruktur für "Frontier"-AI-Modelle wider. Durch das Angebot von 1,5-mal mehr GPU TFLOPS bei FP4-Präzision im Vergleich zu den Vorgängern positioniert sich AWS als primäre Anlaufstelle für Organisationen, die Modelle mit Billionen von Parametern entwickeln. Der Übergang zu HBM3e-Speicher und PCIe Gen6-Konnektivität adressiert die primären Engpässe bei der AI-Skalierung: Speicherkapazität und Interconnect-Geschwindigkeit.
Für CTOs und AI-Strategen bietet dieser Launch einen klaren Pfad zur Skalierung von Operationen, ohne dass sofortige Investitionen in On-Premises-Hardware erforderlich sind. Die Verfügbarkeit dieser Instanzen in wichtigen AWS-Regionen ermöglicht den sofortigen Einsatz von Hochleistungs-Clustern. Da die Nachfrage nach multimodaler AI und hochentwickelten Reasoning-Modellen wächst, ist der Zugang zu Blackwell Ultra Silizium über die Cloud ein entscheidender Wettbewerbsvorteil für Unternehmen, die die Time-to-Market für neue AI-Produkte minimieren wollen. Diese Flexibilität ist besonders wertvoll für Startups, die während der finalen Trainingsphasen ihrer Modelle kurzfristig enorme Rechenkapazitäten benötigen.
AWS bestätigte, dass die Größe p6-b300.48xlarge die primäre Konfiguration für diese Instanzen ist. Organisationen können ab sofort mit der Bereitstellung dieser Ressourcen über die AWS Management Console oder das Command Line Interface beginnen, um ihre anspruchsvollsten Machine-Learning-Projekte zu unterstützen. Das Unternehmen gab an, dass diese Instanzen für die neuesten Ultraserver-Architekturen optimiert sind, die bis zu 13.320 GB GPU-Speicher über einen einzelnen Cluster für massive parallelverarbeitende Aufgaben aggregieren können.
Obwohl wir uns um Genauigkeit bemühen, kann bytevyte Fehler machen. Nutzern wird empfohlen, alle Informationen unabhängig zu überprüfen. Wir übernehmen keine Haftung für Fehler oder Auslassungen.
Related Articles
- AWS integriert NVIDIA Blackwell GPUs in SageMaker mit neuen G7e-Instanzen
- Amazon Bedrock integriert OpenAI GPT OSS und NVIDIA Nemotron zur Diversifizierung von Enterprise-AI-Optionen
- Intel und Google Cloud steigern AI-Performance mit Xeon 6 und Custom Silicon
✔Human Verified