AWS lance les instances Amazon EC2 P6-B300 équipées de GPU NVIDIA Blackwell Ultra
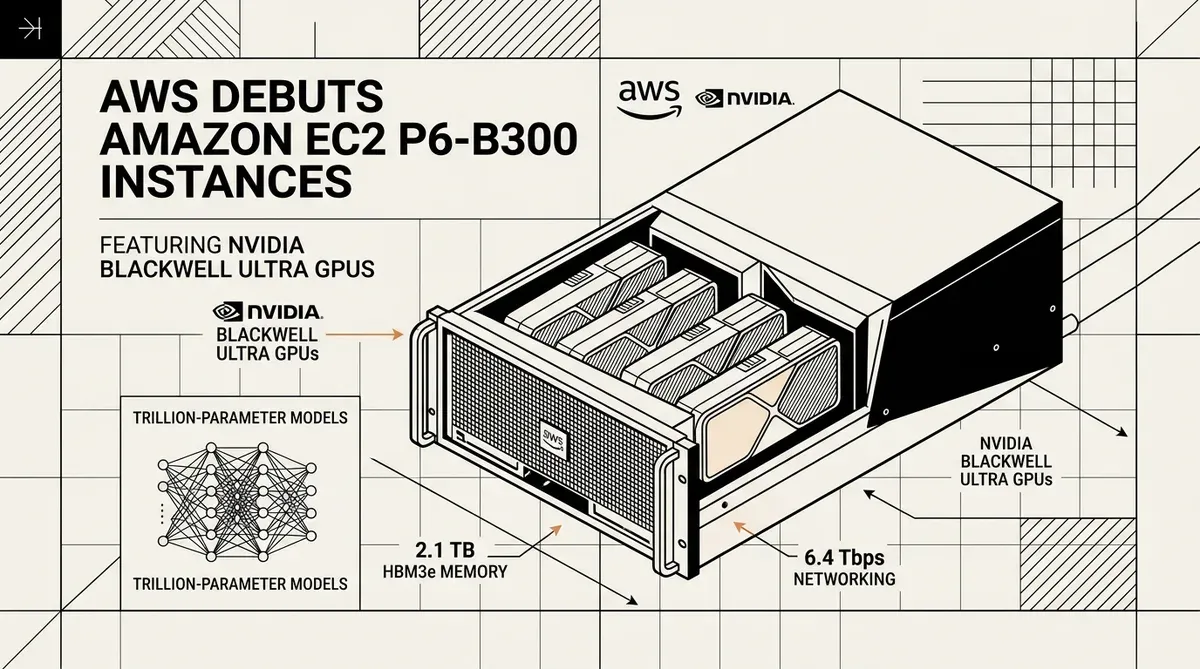
Amazon Web Services a lancé les instances Amazon EC2 P6-B300, marquant une mise à niveau significative de l'infrastructure cloud pour l'entraînement de modèles de fondation comptant des milliers de milliards de paramètres. Ces nouvelles instances, propulsées par les GPU NVIDIA Blackwell Ultra, sont désormais disponibles dans les régions US East (N. Virginia) et US West (Oregon) depuis mai 2026. Cette sortie cible les décideurs d'entreprise et les chercheurs en IA qui nécessitent une puissance de calcul massive pour la prochaine génération de grands modèles de langage.
La plateforme Amazon EC2 P6-B300 intègre huit GPU NVIDIA Blackwell Ultra par instance, offrant un bond substantiel de performance par rapport aux générations précédentes. Chaque instance dispose de 2,1 To de mémoire GPU à haute bande passante (HBM3e), soit une augmentation de 50 % par rapport aux modèles P6-B200. Cette extension de mémoire permet de conserver des poids de modèles plus importants localement sur le GPU, réduisant ainsi le besoin d'échanges de données fréquents et accélérant l'entraînement de réseaux de neurones complexes.
Spécifications techniques et performances réseau
Au-delà de la puissance brute des GPU, les instances Amazon EC2 P6-B300 introduisent des améliorations majeures dans le mouvement des données et la mémoire système. Conçues sur l'AWS Nitro System, ces instances déchargent les fonctions d'E/S et de sécurité vers du matériel dédié, garantissant que les ressources de calcul primaires restent concentrées sur les charges de travail d'IA. La mémoire système a été portée à 4 096 Gio pour soutenir la nature intensive en données des pipelines d'IA modernes.
Le débit réseau voit sa capacité doubler grâce à l'implémentation de l'EFAv4 (Elastic Fabric Adapter). Les instances délivrent une bande passante réseau de 6,4 Tbps, ainsi qu'un débit ENA (Elastic Network Adapter) dédié de 300 Gbps. Cette interconnexion à haute vitesse est essentielle pour l'entraînement distribué, où des milliers de GPU doivent communiquer avec une latence minimale pour synchroniser les gradients des modèles. L'intégration du PCIe Gen6 soutient également ce débit en doublant les taux de transfert de données internes entre les composants du système.
- 8x GPU NVIDIA Blackwell Ultra par instance.
- 2 144 Go de mémoire GPU HBM3e.
- Bande passante réseau EFAv4 de 6,4 Tbps.
- 4 096 Gio de mémoire système.
- Intégration PCIe Gen6 pour un transfert de données amélioré.
Implications stratégiques pour le développement de l'IA
L'introduction des instances Amazon EC2 P6-B300 reflète l'intensification de la course pour fournir l'infrastructure nécessaire aux modèles d'IA de « frontière ». En offrant 1,5 fois plus de TFLOPS GPU en précision FP4 que ses prédécesseurs, AWS se positionne comme la destination privilégiée pour les organisations développant des modèles à mille milliards de paramètres. La transition vers la mémoire HBM3e et la connectivité PCIe Gen6 répond aux principaux goulots d'étranglement de la mise à l'échelle de l'IA : la capacité mémoire et la vitesse d'interconnexion.
Pour les CTO et les stratèges en IA, ce lancement offre une voie claire pour mettre à l'échelle les opérations sans investissement immédiat dans du matériel sur site. La disponibilité de ces instances dans les principales régions AWS permet un déploiement immédiat de clusters haute performance. Alors que la demande pour l'IA multimodale et les modèles de raisonnement sophistiqués croît, la capacité d'accéder au silicium Blackwell Ultra via le cloud constitue un avantage concurrentiel clé pour les entreprises cherchant à minimiser le délai de mise sur le marché de nouveaux produits d'IA. Cette flexibilité est particulièrement utile pour les startups qui ont besoin d'augmenter ponctuellement leur capacité de calcul lors des phases finales d'entraînement des modèles.
AWS a confirmé que la taille p6-b300.48xlarge est la configuration principale pour ces instances. Les organisations peuvent désormais commencer à provisionner ces ressources via la console de gestion AWS ou l'interface de ligne de commande pour soutenir leurs projets d'apprentissage automatique les plus exigeants. L'entreprise a indiqué que ces instances sont optimisées pour les dernières architectures Ultraserver, capables d'agréger jusqu'à 13 320 Go de mémoire GPU sur un seul cluster pour des tâches de traitement parallèle massif.
Bien que nous nous efforcions d'être précis, bytevyte peut commettre des erreurs. Il est conseillé aux utilisateurs de vérifier toutes les informations de manière indépendante. Nous déclinons toute responsabilité pour les erreurs ou omissions.
Related Articles
- AWS intègre les GPU NVIDIA Blackwell dans SageMaker avec les nouvelles instances G7e
- Amazon Bedrock intègre OpenAI GPT OSS et NVIDIA Nemotron pour diversifier les options d'IA en entreprise
- Intel et Google Cloud boostent les performances de l'IA avec Xeon 6 et du silicium personnalisé
✔Human Verified