AWS lancia le istanze Amazon EC2 P6-B300 con GPU NVIDIA Blackwell Ultra
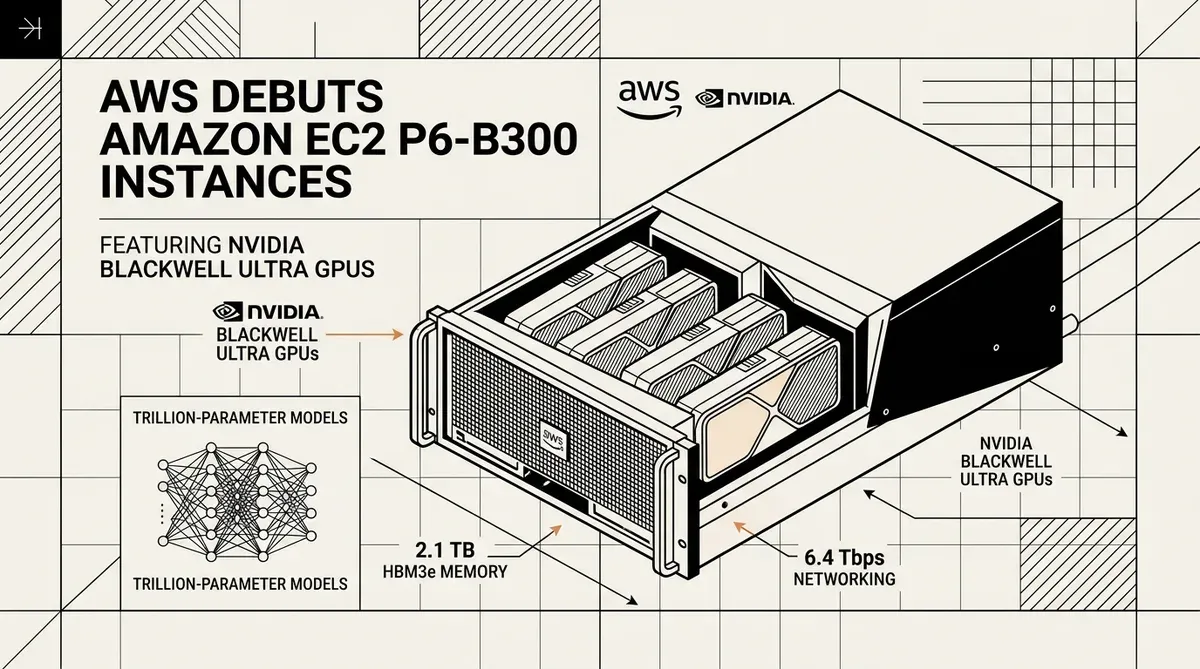
Amazon Web Services ha lanciato le istanze Amazon EC2 P6-B300, segnando un aggiornamento significativo nell'infrastruttura cloud per l'addestramento di modelli di base da trilioni di parametri. Queste nuove istanze, basate su NVIDIA Blackwell Ultra GPUs, sono ora disponibili nelle regioni US East (N. Virginia) e US West (Oregon) a partire da maggio 2026. Il rilascio si rivolge ai decision-maker aziendali e ai ricercatori di AI che richiedono una scala computazionale massiccia per la prossima generazione di modelli linguistici di grandi dimensioni.
La piattaforma Amazon EC2 P6-B300 integra otto GPU NVIDIA Blackwell Ultra per istanza, fornendo un salto sostanziale nelle prestazioni rispetto alle generazioni precedenti. Ogni istanza dispone di 2,1 TB di memoria GPU ad alta larghezza di banda (HBM3e), con un aumento del 50% rispetto ai modelli P6-B200. Questa espansione di memoria consente di mantenere pesi di modello più grandi localmente sulla GPU, riducendo la necessità di frequenti scambi di dati e accelerando l'addestramento di reti neurali complesse.
Specifiche tecniche e prestazioni di networking
Oltre alla pura potenza della GPU, le istanze Amazon EC2 P6-B300 introducono importanti miglioramenti nel movimento dei dati e nella memoria di sistema. Basate su AWS Nitro System, queste istanze delegano le funzioni di I/O e sicurezza a hardware dedicato, garantendo che le risorse di calcolo primarie rimangano focalizzate sui carichi di lavoro AI. La memoria di sistema è stata scalata a 4.096 GiB per supportare la natura intensiva di dati delle moderne pipeline di AI.
Il throughput di rete vede un raddoppio della capacità grazie all'implementazione di EFAv4 (Elastic Fabric Adapter). Le istanze offrono 6,4 Tbps di larghezza di banda di rete, insieme a 300 Gbps di throughput ENA (Elastic Network Adapter) dedicato. Questa interconnessione ad alta velocità è essenziale per l'addestramento distribuito, dove migliaia di GPU devono comunicare con una latenza minima per sincronizzare i gradienti del modello. L'integrazione di PCIe Gen6 supporta ulteriormente questo throughput raddoppiando i tassi di trasferimento dati interni tra i componenti del sistema.
- 8x GPU NVIDIA Blackwell Ultra per istanza.
- 2.144 GB di memoria GPU HBM3e.
- Larghezza di banda di rete EFAv4 da 6,4 Tbps.
- 4.096 GiB di memoria di sistema.
- Integrazione PCIe Gen6 per un trasferimento dati ottimizzato.
Implicazioni strategiche per lo sviluppo dell'AI
L'introduzione delle istanze Amazon EC2 P6-B300 riflette l'intensificarsi della corsa per fornire l'infrastruttura necessaria ai modelli AI di "frontiera". Offrendo 1,5 volte più TFLOPS GPU con precisione FP4 rispetto ai suoi predecessori, AWS si posiziona come la destinazione primaria per le organizzazioni che sviluppano modelli da trilioni di parametri. Il passaggio alla memoria HBM3e e alla connettività PCIe Gen6 affronta i principali colli di bottiglia nello scaling dell'AI: la capacità di memoria e la velocità di interconnessione.
Per i CTO e gli strateghi dell'AI, questo lancio fornisce un percorso chiaro per scalare le operazioni senza la necessità immediata di investimenti in hardware on-premises. La disponibilità di queste istanze nelle principali regioni AWS consente l'implementazione immediata di cluster ad alte prestazioni. Con la crescita della domanda di AI multimodale e modelli di ragionamento sofisticati, la possibilità di accedere al silicio Blackwell Ultra tramite il cloud rappresenta un vantaggio competitivo chiave per le aziende che cercano di ridurre il time-to-market per i nuovi prodotti AI. Questa flessibilità è particolarmente utile per le startup che necessitano di picchi di capacità di calcolo durante le fasi finali di addestramento del modello.
AWS ha confermato che la dimensione p6-b300.48xlarge è la configurazione primaria per queste istanze. Le organizzazioni possono ora iniziare a fornire queste risorse tramite la AWS Management Console o la Command Line Interface per supportare i loro progetti di machine learning più impegnativi. L'azienda ha indicato che queste istanze sono ottimizzate per le ultime architetture Ultraserver, che possono aggregare fino a 13.320 GB di memoria GPU in un singolo cluster per attività di elaborazione parallela massiccia.
Sebbene ci impegniamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Related Articles
- AWS integra le GPU NVIDIA Blackwell in SageMaker con le nuove istanze G7e
- Amazon Bedrock integra OpenAI GPT OSS e NVIDIA Nemotron per diversificare le opzioni AI aziendali
- Intel e Google Cloud potenziano le prestazioni AI con Xeon 6 e silicio personalizzato
✔Human Verified