Databricks automatise l'intégration des données avec la nouvelle fonctionnalité Native Lakehouse Sync
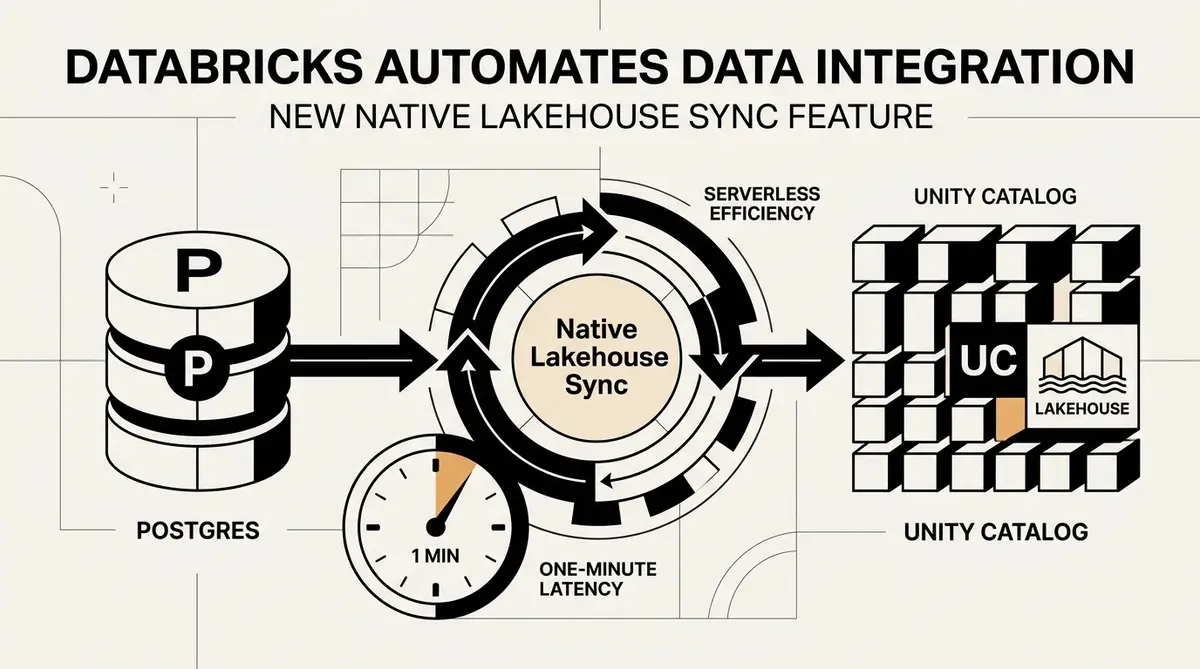
Databricks a lancé la préversion publique de Native Lakehouse Sync, une capacité serverless conçue pour automatiser l'intégration des données depuis des bases de données externes directement dans le Unity Catalog. Cette nouvelle fonctionnalité, annoncée le 12 mai 2026, permet aux organisations de répliquer des données provenant de sources telles que Postgres dans des tables gérées sans avoir à maintenir de ressources de calcul externes ni à construire des pipelines ETL personnalisés. En supprimant ces exigences d'infrastructure, la plateforme vise à réduire la dette technique généralement associée au maintien de la fraîcheur des données pour l'apprentissage automatique et l'analyse opérationnelle.
L'introduction de Native Lakehouse Sync répond à un goulot d'étranglement persistant dans l'architecture des données d'entreprise : le décalage entre les bases de données opérationnelles et les environnements analytiques. Databricks affirme que le système atteint une latence de synchronisation d'environ une minute. Cette performance en quasi-temps réel est destinée à prendre en charge les fonctionnalités de machine learning en direct et le suivi de l'historique des données opérationnelles via le support des dimensions à changement lent (SCD) de type 2. Comme l'architecture est serverless, elle s'ajuste à zéro lorsqu'elle n'est pas utilisée, réduisant potentiellement le coût total de possession pour les tâches d'ingestion de données.
Impact stratégique de Native Lakehouse Sync
Pour les responsables techniques, la valeur principale de Native Lakehouse Sync réside dans sa capacité à gérer la propagation automatique des schémas. Lorsque les tables sources changent, les tables gérées du Unity Catalog se mettent à jour en conséquence, réduisant l'intervention manuelle requise par les ingénieurs de données. Cette automatisation est un élément clé de la stratégie de Databricks visant à consolider la gouvernance et le traitement des données au sein d'un environnement unique, distançant davantage le modèle lakehouse des architectures de data warehouse traditionnelles et fragmentées.
Cette initiative intensifie également la concurrence sur le marché du mouvement automatisé des données. En intégrant l'ingestion native directement dans la plateforme, Databricks réduit la dépendance aux outils d'intégration tiers. Cette intégration garantit que les données restent dans le périmètre de sécurité et de gouvernance du Unity Catalog dès le moment de l'ingestion. Pour les entreprises, cela signifie un parcours plus fluide entre les données brutes d'une base de données transactionnelle et un modèle ou un tableau de bord prêt pour la production.
Depuis mai 2026, le service est disponible en préversion publique pour les sources Postgres via Lakebase. Databricks a indiqué qu'il s'agissait de la première étape d'un déploiement plus large de connecteurs natifs conçus pour simplifier le cycle de vie des données. Les organisations souhaitant implémenter cette fonctionnalité peuvent désormais y accéder via leurs configurations d'espace de travail existantes pour commencer à migrer leurs charges de travail vers le framework de synchronisation serverless.
Bien que nous nous efforcions d'être précis, bytevyte peut commettre des erreurs. Il est conseillé aux utilisateurs de vérifier toutes les informations de manière indépendante. Nous déclinons toute responsabilité en cas d'erreurs ou d'omissions.
Related Articles
- Databricks lance le Genie Agent Mode pour l'analyse de données
- LangGuard déploie la gouvernance des flux de travail agentiques sur Lakebase
- Databricks Unity AI Gateway ajoute une gouvernance pour l'IA agentique
✔Human Verified