Databricks automatisiert die Datenintegration mit der neuen Native Lakehouse Sync-Funktion
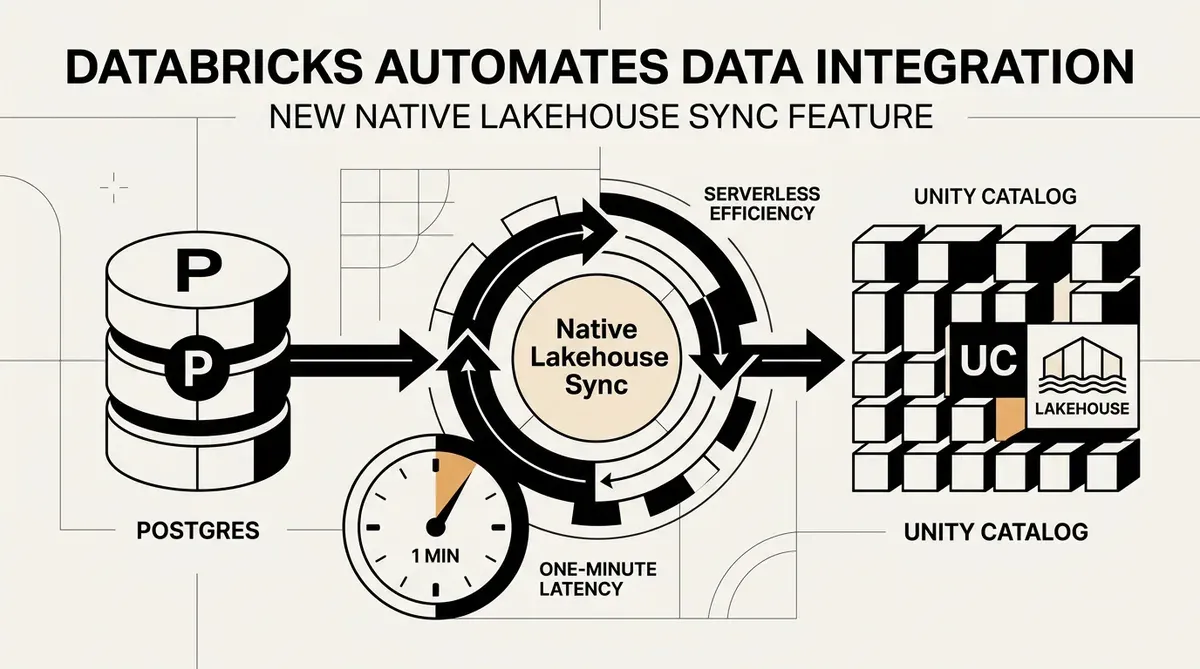
Databricks hat die Public Preview von Native Lakehouse Sync gestartet, einer serverlosen Funktion zur Automatisierung der Datenintegration aus externen Datenbanken direkt in den Unity Catalog. Diese neue Funktion, die am 12. Mai 2026 angekündigt wurde, ermöglicht es Unternehmen, Daten aus Quellen wie Postgres in verwaltete Tabellen zu replizieren, ohne externe Rechenressourcen warten oder benutzerdefinierte ETL-Pipelines erstellen zu müssen. Durch den Wegfall dieser Infrastrukturanforderungen zielt die Plattform darauf ab, die technische Schuld zu reduzieren, die normalerweise mit der Aufrechterhaltung der Datenaktualität für Machine Learning und operative Analysen verbunden ist.
Die Einführung von Native Lakehouse Sync adressiert einen hartnäckigen Engpass in der Datenarchitektur von Unternehmen: die Verzögerung zwischen operativen Datenbanken und Analyseumgebungen. Databricks gibt an, dass das System eine Synchronisationslatenz von etwa einer Minute erreicht. Diese Near-Real-Time-Performance soll Live-Machine-Learning-Features und die Verfolgung der operativen Datenhistorie durch Unterstützung von Slowly Changing Dimension (SCD) Typ 2 unterstützen. Da die Architektur serverlos ist, skaliert sie bei Nichtgebrauch auf Null, was potenziell die Gesamtkosten für Daten-Ingestion-Aufgaben senkt.
Strategische Auswirkungen von Native Lakehouse Sync
Für technische Führungskräfte liegt der Hauptvorteil von Native Lakehouse Sync in der Fähigkeit zur automatischen Schema-Propagierung. Wenn sich Quelltabellen ändern, werden die vom Unity Catalog verwalteten Tabellen entsprechend aktualisiert, was den manuellen Aufwand für Dateningenieure reduziert. Diese Automatisierung ist ein zentraler Bestandteil der Databricks-Strategie, die Daten-Governance und -Verarbeitung in einer einzigen Umgebung zu konsolidieren und das Lakehouse-Modell weiter von traditionellen, fragmentierten Data-Warehouse-Architekturen abzugrenzen.
Der Schritt verschärft zudem den Wettbewerb im Markt für automatisierte Datenbewegungen. Durch die Integration nativer Ingestion direkt in die Plattform reduziert Databricks die Abhängigkeit von Drittanbieter-Integrationstools. Diese Integration stellt sicher, dass die Daten vom Moment der Ingestion an innerhalb des Sicherheits- und Governance-Perimeters des Unity Catalog verbleiben. Für Unternehmen bedeutet dies einen effizienteren Weg von Rohdaten in einer Transaktionsdatenbank hin zu einem produktionsreifen Modell oder Dashboard.
Seit Mai 2026 ist der Dienst als Public Preview für Postgres-Quellen via Lakebase verfügbar. Databricks hat angedeutet, dass dies der erste Schritt eines umfassenderen Rollouts nativer Connectors ist, die den Datenlebenszyklus vereinfachen sollen. Unternehmen, die diese Funktion implementieren möchten, können ab sofort über ihre bestehenden Workspace-Konfigurationen darauf zugreifen, um Workloads in das serverlose Synchronisations-Framework zu migrieren.
Obwohl wir uns um Genauigkeit bemühen, kann bytevyte Fehler machen. Benutzern wird empfohlen, alle Informationen unabhängig zu überprüfen. Wir übernehmen keine Haftung für Fehler oder Auslassungen.
Related Articles
- Databricks führt No-Code Excel-Integration ein, um den Zugriff auf Lakehouse-Daten zu demokratisieren
- Databricks führt Genie Agent Mode für die Datenanalyse ein
- LangGuard skaliert Agentic Workflow Governance auf Lakebase
✔Human Verified