Databricks automatizza l'integrazione dei dati con la nuova funzionalità Native Lakehouse Sync
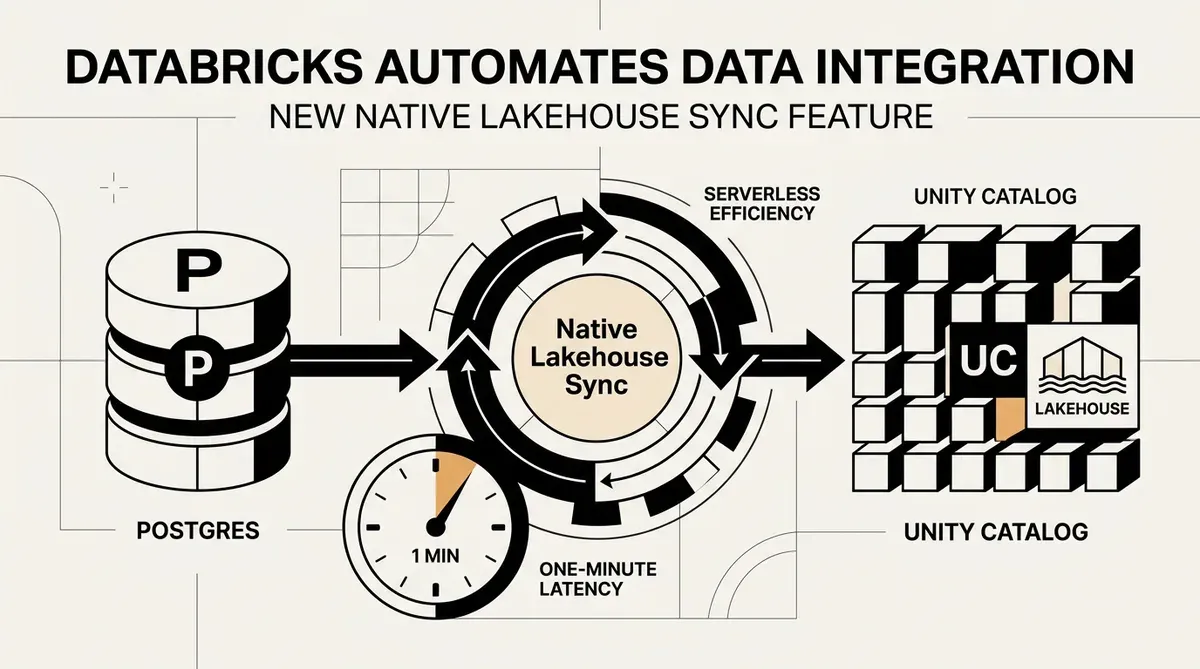
Databricks ha lanciato la public preview di Native Lakehouse Sync, una funzionalità serverless progettata per automatizzare l'integrazione dei dati da database esterni direttamente nel Unity Catalog. Questa nuova funzione, annunciata il 12 maggio 2026, consente alle organizzazioni di replicare i dati da sorgenti come Postgres in tabelle gestite senza dover mantenere risorse di calcolo esterne o creare pipeline ETL personalizzate. Rimuovendo questi requisiti infrastrutturali, la piattaforma mira a ridurre il debito tecnico tipicamente associato al mantenimento della freschezza dei dati per il machine learning e l'analisi operativa.
L'introduzione di Native Lakehouse Sync affronta un collo di bottiglia persistente nell'architettura dei dati aziendali: il ritardo tra i database operativi e gli ambienti analitici. Databricks dichiara che il sistema raggiunge una latenza di sincronizzazione di circa un minuto. Questa performance quasi in tempo reale è destinata a supportare funzionalità di machine learning live e il tracciamento dello storico dei dati operativi attraverso il supporto per Slowly Changing Dimension (SCD) Type 2. Poiché l'architettura è serverless, scala a zero quando non è in uso, riducendo potenzialmente il costo totale di proprietà per le attività di ingestione dei dati.
Impatto strategico di Native Lakehouse Sync
Per i leader tecnici, il valore primario di Native Lakehouse Sync risiede nella sua capacità di gestire la propagazione automatica dello schema. Quando le tabelle sorgente cambiano, le tabelle gestite di Unity Catalog si aggiornano di conseguenza, riducendo l'intervento manuale richiesto dai data engineer. Questa automazione è una parte fondamentale della strategia di Databricks per consolidare la governance e l'elaborazione dei dati all'interno di un unico ambiente, distanziando ulteriormente il modello lakehouse dalle tradizionali e frammentate architetture di data warehouse.
La mossa intensifica anche la competizione nel mercato del movimento automatizzato dei dati. Integrando l'ingestione nativa direttamente nella piattaforma, Databricks riduce la dipendenza da strumenti di integrazione di terze parti. Questa integrazione garantisce che i dati rimangano all'interno del perimetro di sicurezza e governance di Unity Catalog fin dal momento dell'ingestione. Per le aziende, ciò significa un percorso più snello dai dati grezzi in un database transazionale a un modello o una dashboard pronti per la produzione.
A partire da maggio 2026, il servizio è disponibile in public preview per sorgenti Postgres tramite Lakebase. Databricks ha indicato che questo è il primo passo di una più ampia distribuzione di connettori nativi progettati per semplificare il ciclo di vita dei dati. Le organizzazioni che desiderano implementare questa funzionalità possono ora accedervi tramite le configurazioni esistenti del proprio workspace per iniziare a migrare i carichi di lavoro nel framework di sincronizzazione serverless.
Sebbene ci impegniamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Related Articles
- Databricks lancia l'integrazione Excel no-code per democratizzare l'accesso ai dati del Lakehouse
- LangGuard scala la Agentic Workflow Governance su Lakebase
- Databricks Unity AI Gateway aggiunge la governance per l'AI agentica
✔Human Verified