Databricks abilita l'accesso di engine esterni a Unity Catalog tramite API aperte
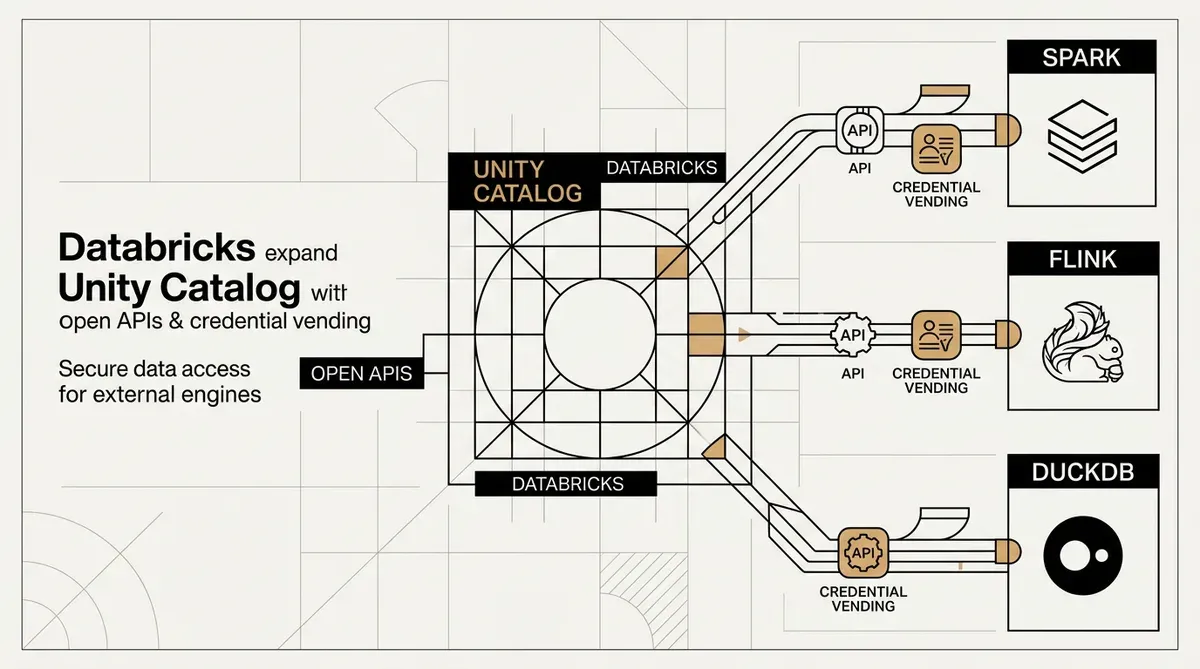
Databricks ha aumentato l'interoperabilità del suo Unity Catalog lanciando API aperte e rendendo generalmente disponibile il credential vending. Questi aggiornamenti consentono ad ambienti di calcolo di terze parti di interagire con le Delta tables gestite. Strumenti come Apache Spark, Flink e DuckDB possono ora eseguire operazioni complete sui dati, inclusa la creazione e l'aggiornamento di tabelle, direttamente all'interno del catalogo. Il sistema utilizza un nuovo standard aperto per i commit del catalogo al fine di mantenere l'integrità transazionale e supportare scritture simultanee su diverse piattaforme.
L'aggiornamento rimuove le barriere tecniche associate ai sistemi proprietari di data governance. Aprendo Unity Catalog, Databricks consente alle aziende di utilizzare un unico livello di governance scegliendo al contempo engine di elaborazione specifici per diversi task. La sicurezza per le pipeline a lunga esecuzione è gestita tramite OAuth machine-to-machine (M2M) e l'aggiornamento automatico delle credenziali.
Dettagli tecnici del Credential Vending
Il credential vending è ora generalmente disponibile per l'accesso sicuro ai dati. Questo sistema emette token temporanei ad accesso limitato verso engine di calcolo esterni, sostituendo la necessità di credenziali statiche permanenti. Databricks ha inoltre lanciato una public preview di questa funzionalità per i Volumes. Questa estensione fornisce un accesso governato a tipi di dati non strutturati, inclusi file video e immagini.
L'uso di API aperte nell'ambiente Unity Catalog offre maggiore flessibilità per i sistemi AI aziendali. Man mano che le organizzazioni sviluppano modelli AI più avanzati, richiedono un accesso sicuro ai dati governati attraverso molteplici engine. Databricks prevede di aggiungere controlli di accesso basati sugli attributi (ABAC) nelle versioni successive. Questi controlli consentiranno agli amministratori di impostare policy di sicurezza a livello di riga e colonna per le letture di dati esterni.
Sono disponibili anche nuove funzionalità di performance. La Predictive Optimization aumenta la velocità delle query fino a 20 volte e riduce le spese di storage del 50 percento. Questi miglioramenti mirano a ridurre il costo totale di gestione di grandi set di dati mantenendo un ampio accesso a Unity Catalog.
Il framework ampliato di Unity Catalog integra le Delta tables in workflow più diversificati. Databricks sta utilizzando standard aperti per i commit transazionali per rendere il suo livello di governance un connettore standard per i data stack. Le organizzazioni possono utilizzare DuckDB per task di dati locali o Flink per lo streaming, mantenendo la sicurezza e l'auditing centralizzati in Unity Catalog.
Sebbene ci impegniamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Related Articles
- Databricks automatizza l'integrazione dei dati con la nuova funzionalità Native Lakehouse Sync
- Databricks Unity AI Gateway aggiunge la governance per l'AI agentica
- Databricks lancia l'integrazione Excel no-code per democratizzare l'accesso ai dati del Lakehouse
✔Human Verified