Databricks permet l'accès des moteurs externes à Unity Catalog via des API ouvertes
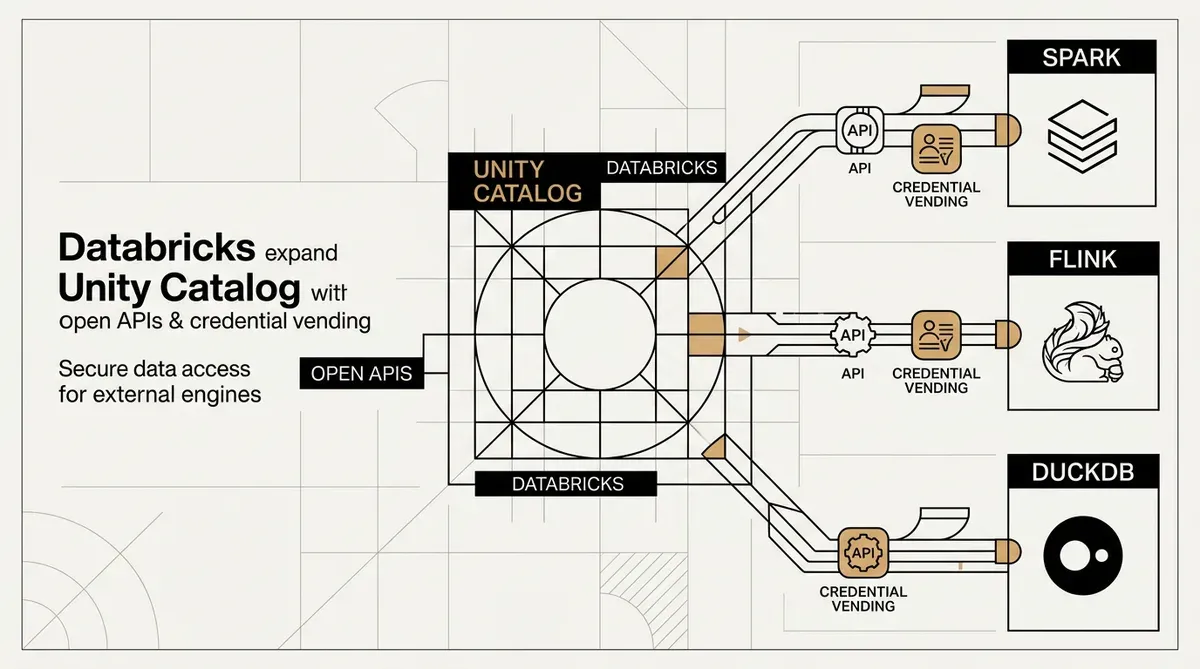
Databricks a renforcé l'interopérabilité de son Unity Catalog en lançant des API ouvertes et en rendant la distribution de jetons d'accès (credential vending) généralement disponible. Ces mises à jour permettent aux environnements de calcul tiers d'interagir avec les Delta tables gérées. Des outils tels qu'Apache Spark, Flink et DuckDB peuvent désormais exécuter des opérations de données complètes, y compris la création et la mise à jour de tables, directement au sein du catalogue. Le système utilise un nouveau standard ouvert pour les validations de catalogue (catalog commits) afin de maintenir l'intégrité transactionnelle et de prendre en charge les écritures simultanées sur différentes plateformes.
La mise à jour lève les barrières techniques associées aux systèmes de gouvernance de données propriétaires. En ouvrant Unity Catalog, Databricks permet aux entreprises d'utiliser une couche de gouvernance unique tout en choisissant des moteurs de traitement spécifiques pour différentes tâches. La sécurité des pipelines à exécution longue est gérée via OAuth de machine à machine (M2M) et le rafraîchissement automatisé des identifiants.
Détails techniques de la distribution de jetons d'accès
La distribution de jetons d'accès (credential vending) est désormais généralement disponible pour un accès sécurisé aux données. Ce système délivre des jetons temporaires à accès limité aux moteurs de calcul externes, ce qui remplace le besoin d'identifiants statiques permanents. Databricks a également lancé une version préliminaire publique de cette fonctionnalité pour les Volumes. Cette extension offre un accès gouverné aux types de données non structurées, y compris les fichiers vidéo et image.
L'utilisation d'API ouvertes dans l'environnement Unity Catalog offre plus de flexibilité pour les systèmes d'IA d'entreprise. À mesure que les organisations conçoivent des modèles d'IA plus avancés, elles nécessitent un accès sécurisé aux données gouvernées à travers plusieurs moteurs. Databricks prévoit d'ajouter des contrôles d'accès basés sur les attributs (ABAC) dans les versions ultérieures. Ces contrôles permettront aux administrateurs de définir des politiques de sécurité au niveau des lignes et des colonnes pour les lectures de données externes.
De nouvelles fonctionnalités de performance sont également disponibles. Predictive Optimization augmente la vitesse des requêtes jusqu'à 20 fois et réduit les frais de stockage de 50 %. Ces améliorations visent à réduire le coût total de gestion des grands ensembles de données tout en maintenant un large accès à Unity Catalog.
Le cadre étendu de Unity Catalog intègre les Delta tables dans des flux de travail plus diversifiés. Databricks utilise des standards ouverts pour les validations transactionnelles afin de faire de sa couche de gouvernance un connecteur standard pour les piles de données. Les organisations peuvent utiliser DuckDB pour les tâches de données locales ou Flink pour le streaming tout en gardant la sécurité et l'audit centralisés dans Unity Catalog.
Bien que nous nous efforcions d'être précis, bytevyte peut commettre des erreurs. Il est conseillé aux utilisateurs de vérifier toutes les informations de manière indépendante. Nous déclinons toute responsabilité en cas d'erreurs ou d'omissions.
Related Articles
- Databricks automatise l'intégration des données avec la nouvelle fonctionnalité Native Lakehouse Sync
- Databricks Unity AI Gateway ajoute une gouvernance pour l'IA agentique
- Databricks lance le Genie Agent Mode pour l'analyse de données
✔Human Verified