Il chip di inferenza Jalapeño di OpenAI riduce i costi del 50%
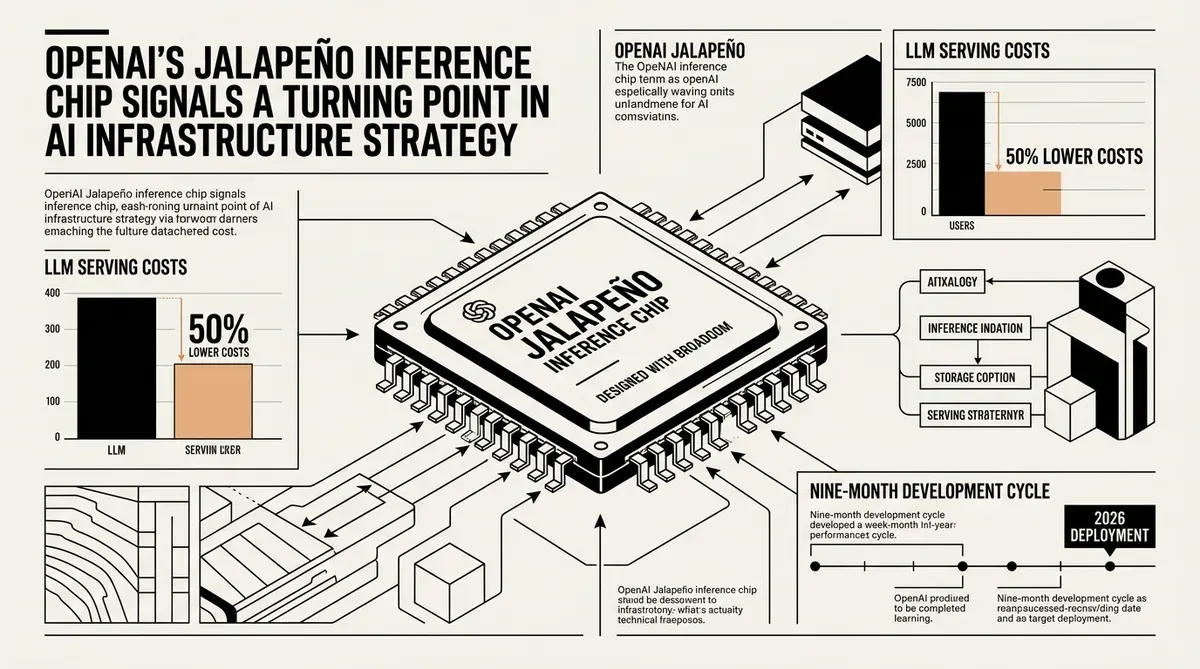
OpenAI ha presentato il chip di inferenza Jalapeño, il primo processore personalizzato per carichi di lavoro con modelli linguistici di grandi dimensioni, una mossa che potrebbe dimezzare i costi di inferenza riducendo la dipendenza da fornitori di GPU di terze parti. Realizzato con Broadcom in nove mesi, l'acceleratore è progettato per l'inferenza LLM ed è già operativo nei laboratori con modelli di produzione ai livelli di prestazione e potenza target.
Il chip estende la strategia di OpenAI da prodotti e modelli al silicio, rendendola l'ultima grande piattaforma AI a perseguire l'integrazione hardware verticale. In condizioni di laboratorio, il chip ha mostrato un miglioramento significativo delle prestazioni per watt rispetto agli acceleratori attuali, riferisce OpenAI. Bloomberg ha riportato che il chip potrebbe ridurre i costi di inferenza di circa la metà.
Uno sprint di sviluppo di nove mesi
Il ritmo dello sviluppo è tra gli aspetti più sorprendenti dell'annuncio. I progetti ASIC personalizzati richiedono in genere diversi anni dal concept alla produzione, ma OpenAI e Broadcom hanno compresso questa tempistica a nove mesi. OpenAI ha accelerato il processo utilizzando i propri modelli di generazione precedente per assistere nella progettazione del chip, applicando efficacemente l'esperienza AI dell'azienda all'ingegneria hardware in un ciclo di feedback che ha pochi precedenti nell'industria dei semiconduttori.
Il produttore canadese Celestica gestirà l'integrazione di sistema, costruendo l'infrastruttura server e rack che ospita i chip. Il design incorpora il silicio di rete Tomahawk di Broadcom per la connettività del data center ad alta larghezza di banda, creando una soluzione a livello di sistema piuttosto che un processore standalone. L'integrazione di calcolo e rete in un'architettura unificata del data center suggerisce che OpenAI stia pensando al servizio di inferenza a livello di cluster piuttosto che a livello di singolo chip.
Riduzione dei costi e posizionamento competitivo
La prevista riduzione del 50% dei costi di inferenza affronta uno dei vincoli più persistenti nell'industria AI: la spesa per servire modelli su larga scala. OpenAI gestisce ChatGPT, l'API Codex e una gamma crescente di prodotti agentici, tutti consumano enormi risorse di calcolo. Un chip progettato su misura ottimizzato per questi carichi di lavoro può ridurre i costi operativi rispetto a GPU generiche che comportano overhead per grafica e carichi di training di cui il chip non ha bisogno.
L'amministratore delegato di Broadcom, Hock Tan, ha descritto il chip di inferenza Jalapeño come competitivo con l'architettura Blackwell di Nvidia e il TPU di Google, posizionandolo allo stesso livello degli acceleratori che alimentano le più grandi implementazioni AI a livello globale. Questo confronto segnala che il processore è progettato per operazioni iperscalabili piuttosto che per applicazioni di nicchia. Per OpenAI, eguagliare le prestazioni di classe Blackwell riducendo il costo per token rappresenterebbe un vantaggio operativo significativo.
Implicazioni strategiche per OpenAI e l'industria
Il lancio ha implicazioni che vanno oltre l'infrastruttura di OpenAI. Nvidia ha dominato il mercato degli acceleratori AI per anni, con una domanda che ha costantemente superato l'offerta e prezzi rimasti elevati. Un chip personalizzato dà a OpenAI leva nelle trattative di approvvigionamento e riduce la sua dipendenza da un unico fornitore in un momento in cui i budget di calcolo crescono rapidamente in tutto il settore.
Il responsabile hardware di OpenAI, Richard Ho, ha dichiarato che l'architettura è progettata per rimanere performante attraverso le future generazioni di LLM, suggerendo che l'azienda considera lo sviluppo di chip come una capacità permanente piuttosto che un progetto una tantum. OpenAI prevede di distribuire il processore nei data center attivi entro la fine del 2026, con una roadmap multi-generazionale già stabilita. La velocità di questa prima generazione solleva domande su quanto rapidamente potrebbero seguire le versioni successive.
La partnership con Broadcom è di per sé strategicamente significativa. Broadcom ha costruito acceleratori personalizzati per la linea TPU di Google e altri clienti iperscalabili, portando una comprovata esperienza nella progettazione ASIC alla collaborazione. Lavorando con un partner consolidato anziché costruire un team interno di chip da zero, OpenAI ha raggiunto la validazione del silicio in meno di un anno. L'accordo dà anche a Broadcom una posizione forte nel mercato dei chip AI insieme alla sua attività esistente di silicio personalizzato.
Distribuzione su larga scala del chip di inferenza Jalapeño
OpenAI ha dichiarato che il chip è progettato per la distribuzione su scala gigawatt, indicando che alimenterà grandi flotte di data center piuttosto che piccoli cluster di inferenza. L'integrazione con il silicio di rete Tomahawk di Broadcom riflette una filosofia di progettazione a livello di sistema: nel servizio di inferenza ad alto rendimento, la larghezza di banda di rete tra gli acceleratori può diventare limitante quanto la capacità di calcolo, quindi ottimizzare l'intero percorso dati è importante quanto il processore stesso.
Il chip è il primo di quella che OpenAI descrive come una piattaforma di calcolo multi-generazionale. Ci si aspetta che ogni iterazione migliori prestazioni, efficienza e costo, seguendo una roadmap iterativa simile ai cicli dell'architettura GPU di Nvidia. Se OpenAI riesce a mantenere il rapido ritmo di sviluppo, potrebbe colmare il divario tra le generazioni di chip più velocemente di quanto consentano le tradizionali roadmap dei semiconduttori.
Contesto di mercato e punti chiave per i decisori
Il chip di inferenza Jalapeño entra in un mercato dove ogni grande fornitore di piattaforme AI ha ora una strategia di silicio personalizzato. Amazon gestisce Trainium e Inferentia, Google sviluppa la linea TPU, Microsoft ha costruito l'acceleratore Maia e Meta ha investito in progetti personalizzati. L'ingresso di OpenAI completa il quadro, ma con una differenza notevole: il chip è focalizzato esclusivamente sull'inferenza piuttosto che sul training, potenzialmente offrendo vantaggi di efficienza che i progetti generici non possono eguagliare per il compito specifico di eseguire LLM.
Per i leader tecnologici che valutano l'infrastruttura AI, il chip segnala che i costi di inferenza probabilmente diminuiranno man mano che il silicio personalizzato diventerà più comune. Le organizzazioni che costruiscono le loro strategie AI partendo dal presupposto che i prezzi delle GPU rimarranno ai livelli attuali potrebbero dover rivedere queste proiezioni. Se i costi interni di OpenAI scendono di circa il 50%, i prezzi delle API per sviluppatori e aziende potrebbero eventualmente seguirne l'esempio, anche se l'azienda potrebbe invece scegliere di migliorare i margini a seconda delle dinamiche competitive con Anthropic, Google e fornitori di modelli a pesi aperti come la serie Llama di Meta.
Il ciclo di sviluppo di nove mesi stabilisce anche un nuovo punto di riferimento per l'industria dei semiconduttori. Se il ritmo può essere sostenuto attraverso più generazioni, la tradizionale tempistica ASIC pluriennale potrebbe subire pressioni per accelerare, in particolare nel segmento AI dove la domanda continua a superare l'offerta. Altri operatori iperscalabili potrebbero trovarsi sotto pressione per eguagliare tempi di realizzazione simili per i loro progetti di silicio personalizzato.
I campioni ingegneristici del processore sono in esecuzione con carichi di lavoro di produzione nei laboratori di OpenAI alla frequenza e potenza target. L'azienda prevede di iniziare a distribuire i chip nei data center attivi entro la fine del 2026, con generazioni successive già in fase di pianificazione. Broadcom e Celestica gestiranno rispettivamente la produzione in volume e l'integrazione di sistema. OpenAI non ha annunciato piani per la disponibilità di terze parti al di fuori della propria infrastruttura, lasciando aperta la domanda se il chip di inferenza Jalapeño potrebbe eventualmente servire un mercato più ampio.
Sources
OpenAI and Broadcom unveil LLM-optimized inference chip
Related Articles
- OpenAI e il wearable AI 'Sweetpea' di Jony Ive: lancio previsto per il 2026
- L'adozione di DeepSeek V4 Pro impenna mentre le aziende USA passano a modelli AI a basso costo
- NVIDIA presenta l'architettura Vera Rubin per abbattere i costi di inferenza AI
✔Human Verified
Ricercato e verificato con fonti primarie dalla redazione di Bytevyte.