NVIDIA and Hugging Face Advance LLM Training with Task-Seeded Synthetic Data Generation
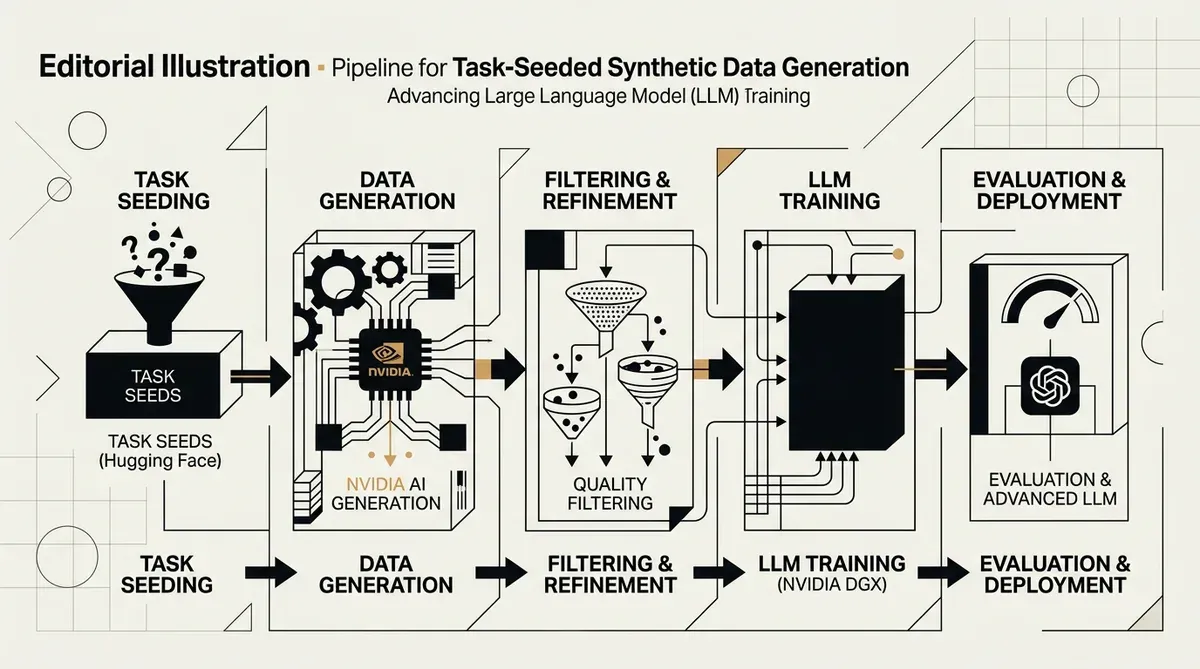
NVIDIA and Hugging Face have introduced a new methodology for task-seeded synthetic data generation, a framework designed to improve the pretraining of large language models by creating high-quality, structured training sets. This collaborative research addresses the growing scarcity of human-generated data by using existing task capabilities as seeds to produce complex synthetic Q&A pairs. The system aims to move beyond simple data replication, focusing instead on transfer learning to boost model performance across diverse domains.
The task-seeded synthetic data generation process follows a five-stage pipeline to ensure the quality and utility of the output. This workflow begins with seed collection, followed by record normalization and example generation. The final stages involve answer enrichment, where reasoning traces are added to the data, and a filtering phase to remove low-quality entries. By using 70 tasks and 700 subtasks from the lm-eval-harness as seeds, the researchers have created a diverse foundation for generating synthetic content that includes both context and logical steps.
Strategic Impact on Model Scaling
The effectiveness of this approach was tested using the Nemotron-3 Nano model in a 100B token continuation experiment. NVIDIA reported that the structured synthetic data improved the model's performance even in areas that were not part of the original seed tasks. This suggests that the method is effective for general capability improvements rather than just memorizing specific datasets. For enterprise leaders, this is a shift in how frontier models can be scaled efficiently without relying solely on increasingly expensive or rare human-curated data.
By enriching synthetic data with reasoning traces, the framework provides models with the logical steps behind an answer, which is a key factor in developing advanced reasoning capabilities. This development is particularly relevant for organizations building specialized models where high-quality domain-specific data is limited. The collaboration between NVIDIA and Hugging Face highlights a trend toward more sophisticated synthetic data pipelines that prioritize structural integrity and logical depth over sheer volume.
As of June 2026, the integration of such synthetic data techniques is becoming a standard part of the AI development lifecycle. The ability to generate high-fidelity training material from a limited set of capability seeds allows for more targeted model improvements. NVIDIA and Hugging Face have made the technical details of this deep-dive available to the research community, signaling a push for broader adoption of structured synthetic data generation in the industry.
While we strive for accuracy, bytevyte can make mistakes. Users are advised to verify all information independently. We accept no liability for errors or omissions.
Sources
Task-Seeded Synthetic Q&A Generation for Nemotron Pretraining
AI-generated image.
Related Articles
- NVIDIA Unveils Physical AI Agent Skills to Accelerate Autonomous System Training
- NVIDIA and HuggingFace Use Synthetic Personas to Localize Korean AI Agents
- NVIDIA Unveils Nemotron-Labs Diffusion for High-Speed Parallel Text Generation
✔Human Verified