Databricks Automatiza Integração de Dados com Novo Recurso Native Lakehouse Sync
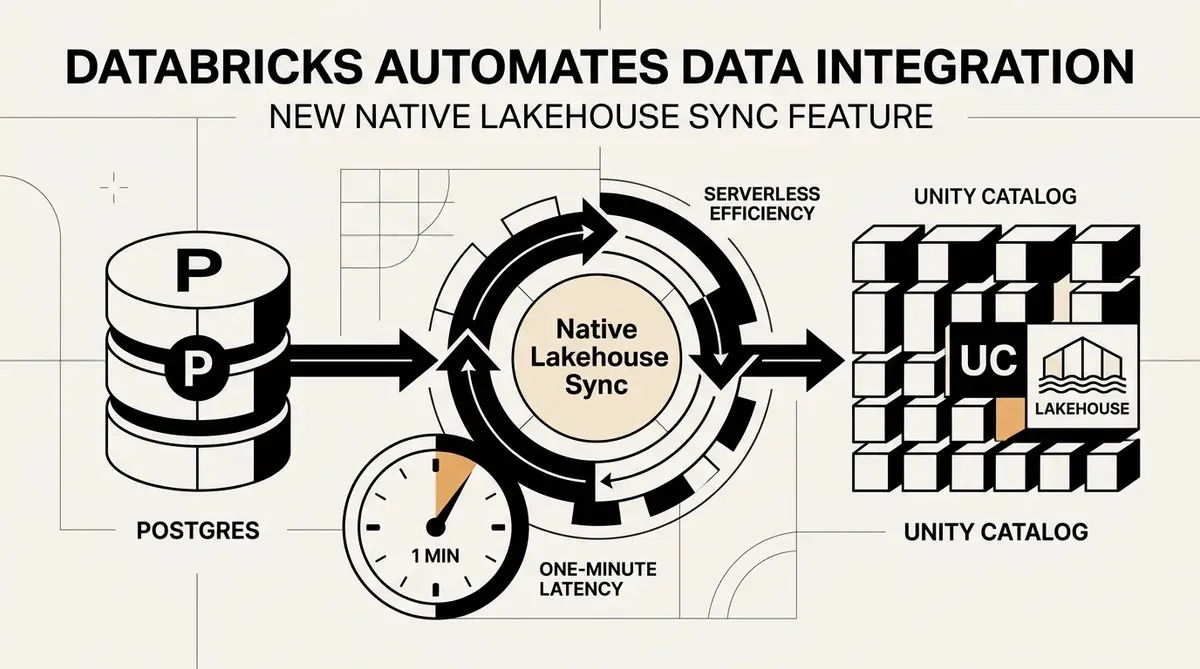
Databricks lançou a prévia pública do Native Lakehouse Sync, uma funcionalidade serverless projetada para automatizar a integração de dados de bancos de dados externos diretamente no Unity Catalog. Este novo recurso, anunciado em 12 de maio de 2026, permite que as organizações repliquem dados de fontes como Postgres em tabelas gerenciadas sem a necessidade de manter recursos de computação externos ou construir pipelines de ETL personalizados. Ao remover esses requisitos de infraestrutura, a plataforma visa reduzir a dívida técnica normalmente associada à manutenção da atualização dos dados para machine learning e análise operacional.
A introdução do Native Lakehouse Sync aborda um gargalo persistente na arquitetura de dados corporativos: o atraso entre os bancos de dados operacionais e os ambientes analíticos. A Databricks afirma que o sistema atinge uma latência de sincronização de aproximadamente um minuto. Esse desempenho em tempo real destina-se a dar suporte a recursos de machine learning ao vivo e ao rastreamento do histórico de dados operacionais por meio do suporte a Slowly Changing Dimension (SCD) Tipo 2. Como a arquitetura é serverless, ela escala para zero quando não está em uso, reduzindo potencialmente o custo total de propriedade para tarefas de ingestão de dados.
Impacto Estratégico do Native Lakehouse Sync
Para líderes técnicos, o valor principal do Native Lakehouse Sync reside em sua capacidade de lidar com a propagação automática de esquema. Quando as tabelas de origem mudam, as tabelas gerenciadas do Unity Catalog são atualizadas adequadamente, reduzindo a intervenção manual exigida pelos engenheiros de dados. Essa automação é uma parte fundamental da estratégia da Databricks para consolidar a governança e o processamento de dados em um único ambiente, distanciando ainda mais o modelo lakehouse das arquiteturas tradicionais e fragmentadas de data warehouse.
A iniciativa também intensifica a competição no mercado de movimentação automatizada de dados. Ao integrar a ingestão nativa diretamente na plataforma, a Databricks está reduzindo a dependência de ferramentas de integração de terceiros. Essa integração garante que os dados permaneçam dentro do perímetro de segurança e governança do Unity Catalog desde o momento da ingestão. Para as empresas, isso significa um caminho mais simplificado desde os dados brutos em um banco de dados transacional até um modelo ou dashboard pronto para produção.
A partir de maio de 2026, o serviço está disponível em prévia pública para fontes Postgres via Lakebase. A Databricks indicou que este é o primeiro passo em um lançamento mais amplo de conectores nativos projetados para simplificar o ciclo de vida dos dados. Organizações que desejam implementar este recurso já podem acessá-lo por meio de suas configurações de workspace existentes para começar a migrar cargas de trabalho para a estrutura de sincronização serverless.
Embora busquemos a precisão, o bytevyte pode cometer erros. Os usuários são aconselhados a verificar todas as informações de forma independente. Não aceitamos qualquer responsabilidade por erros ou omissões.
Related Articles
- Databricks Lança Integração No-Code com Excel para Democratizar o Acesso a Dados no Lakehouse
- Databricks Lança Genie Agent Mode para Análise de Dados
- LangGuard escala agentic workflow governance no Lakebase
✔Human Verified