Databricks automatiza la integración de datos con la nueva función Native Lakehouse Sync
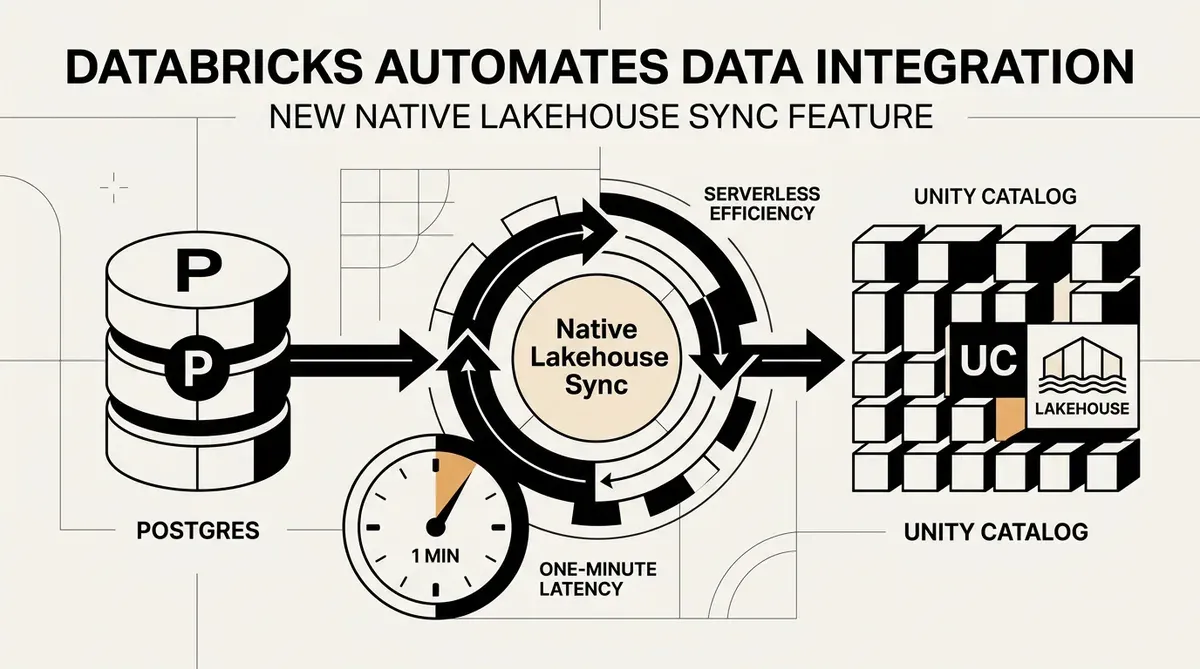
Databricks ha lanzado la vista previa pública de Native Lakehouse Sync, una capacidad serverless diseñada para automatizar la integración de datos desde bases de datos externas directamente en el Unity Catalog. Esta nueva función, anunciada el 12 de mayo de 2026, permite a las organizaciones replicar datos desde fuentes como Postgres en tablas gestionadas sin necesidad de mantener recursos de computación externos ni construir pipelines de ETL personalizados. Al eliminar estos requisitos de infraestructura, la plataforma busca reducir la deuda técnica asociada habitualmente al mantenimiento de la frescura de los datos para el aprendizaje automático y la analítica operativa.
La introducción de Native Lakehouse Sync aborda un cuello de botella persistente en la arquitectura de datos empresarial: el desfase entre las bases de datos operativas y los entornos analíticos. Databricks afirma que el sistema logra una latencia de sincronización de aproximadamente un minuto. Este rendimiento casi en tiempo real está destinado a dar soporte a funciones de aprendizaje automático en vivo y al seguimiento del historial de datos operativos mediante el soporte de Dimensión de Cambio Lento (SCD) Tipo 2. Dado que la arquitectura es serverless, se escala a cero cuando no está en uso, lo que reduce potencialmente el coste total de propiedad de las tareas de ingesta de datos.
Impacto estratégico de Native Lakehouse Sync
Para los líderes técnicos, el valor principal de Native Lakehouse Sync reside en su capacidad para gestionar la propagación automática de esquemas. Cuando las tablas de origen cambian, las tablas gestionadas de Unity Catalog se actualizan en consecuencia, reduciendo la intervención manual requerida por los ingenieros de datos. Esta automatización es una pieza clave de la estrategia de Databricks para consolidar el gobierno y el procesamiento de datos dentro de un único entorno, distanciando aún más el modelo lakehouse de las arquitecturas de almacén de datos tradicionales y fragmentadas.
Este movimiento también intensifica la competencia en el mercado del movimiento automatizado de datos. Al integrar la ingesta nativa directamente en la plataforma, Databricks reduce la dependencia de herramientas de integración de terceros. Esta integración garantiza que los datos permanezcan dentro del perímetro de seguridad y gobernanza de Unity Catalog desde el momento de la ingesta. Para las empresas, esto significa un camino más ágil desde los datos brutos en una base de datos transaccional hasta un modelo o cuadro de mando listo para producción.
A partir de mayo de 2026, el servicio está disponible en vista previa pública para fuentes de Postgres a través de Lakebase. Databricks ha indicado que este es el primer paso en un despliegue más amplio de conectores nativos diseñados para simplificar el ciclo de vida de los datos. Las organizaciones que deseen implementar esta función ya pueden acceder a ella a través de sus configuraciones de espacio de trabajo existentes para comenzar a migrar las cargas de trabajo al marco de sincronización serverless.
Aunque nos esforzamos por la exactitud, bytevyte puede cometer errores. Se aconseja a los usuarios verificar toda la información de forma independiente. No aceptamos ninguna responsabilidad por errores u omisiones.
Related Articles
- Databricks lanza integración sin código con Excel para democratizar el acceso a los datos del Lakehouse
- Databricks lanza Genie Agent Mode para el análisis de datos
- LangGuard escala la agentic workflow governance en Lakebase
✔Human Verified