Databricks optimiert Open-Source-LLM-Performance mit Automated Prompt Caching
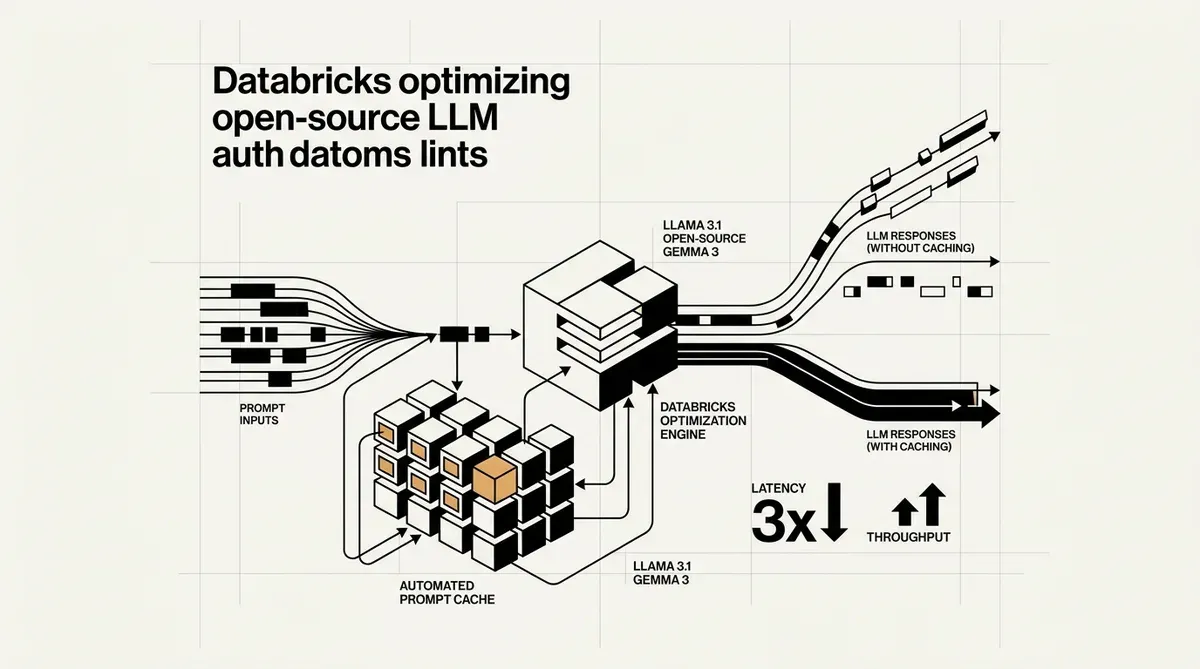
Databricks hat das automated prompt caching für Open-Source Large Language Models eingeführt – ein Schritt, der darauf abzielt, die Betriebskosten bei der Skalierung von KI zu senken. Die neue Funktion, die diese Woche angekündigt wurde, adressiert den hohen Rechenaufwand, der mit der Verarbeitung langer System-Prompts und repetitiver Abfragestrukturen verbunden ist. Durch die Wiederverwendung von Key-Value (KV) Caches für identische Prompt-Präfixe eliminiert die Plattform die Notwendigkeit redundanter Rechenzyklen während der Inferenz.
Die Implementierung von automated prompt caching löst einen erheblichen Engpass in KI-Workflows von Unternehmen. Viele Organisationen nutzen umfangreiche System-Prompts, um das Modellverhalten, Sicherheitsleitplanken oder domänenspezifischen Kontext zu definieren. Bisher mussten diese Anweisungen für jede einzelne Benutzeranfrage neu verarbeitet werden, was zu erhöhter Latenz und höheren Token-Kosten führte. Databricks gab an, dass interne Produktionstests mit GPT-OSS-Modellen eine 3-fache Reduzierung der P50-Latenz und eine 2,5-fache Steigerung des Gesamtdurchsatzes zeigten.
Strategische Auswirkungen auf das Deployment von Open-Source-KI
Dieses Update ist sowohl für Foundation Model APIs (FMAPIs) als auch für Provisioned Throughput Tiers auf der Databricks-Plattform verfügbar. Der Automatisierungsaspekt ist besonders für Entwickler relevant, da keine manuelle Konfiguration erforderlich ist, um das Prefix Caching zu aktivieren. Das System identifiziert wiederkehrende Muster in eingehenden Anfragen und speichert die berechneten Zustände im flüchtigen Speicher. Dieser Ansatz stellt sicher, dass Performance-Gewinne nicht auf Kosten der Datensicherheit gehen, da die gecachten Daten isoliert sind und nicht auf die Festplatte geschrieben werden.
Die Liste der unterstützten Modelle umfasst mehrere hochkarätige Open-Source-Architekturen. Nutzer können diese Technologie mit Llama 3.1 (8B und 70B Varianten), Gemma 3 12B und der GPT-OSS-Familie in den Konfigurationen 20B und 120B nutzen. Durch die Optimierung des Inferenzpfads für diese Modelle positioniert sich Databricks als kosteneffizientere Alternative zu proprietären Modellanbietern für Unternehmen, die die Kontrolle über ihre Gewichte und Daten behalten möchten.
Die Einführung von automated prompt caching folgt einem breiteren Branchentrend zur Inferenzoptimierung. Da Unternehmen von experimentellen Piloten zu produktionsreifen Anwendungen übergehen, hat sich der Fokus von der reinen Modellleistung auf die Wirtschaftlichkeit des Deployments verschoben. Databricks zielt darauf ab, diesen Markt zu erobern, indem die finanzielle Hürde für den Einsatz großer Open-Source-Modelle in Umgebungen mit hohem Volumen gesenkt wird. Die Funktion wird seit dem 23. Mai 2026 für alle Nutzer auf der Plattform ausgerollt.
Obwohl wir uns um Genauigkeit bemühen, kann bytevyte Fehler machen. Benutzern wird empfohlen, alle Informationen unabhängig zu überprüfen. Wir übernehmen keine Haftung für Fehler oder Auslassungen.
Sources
Accelerating LLM Inference with Prompt Caching for Open‑Source Models on Databricks
Related Articles
- Databricks und OpenAI präsentieren GPT-5.5 Enterprise AI Agents
- Databricks: Memory Scaling for AI Agents ist eine zentrale Design-Achse
- Databricks führt Sketch Functions ein, um die Datenschätzung im großen Stil zu optimieren
✔Human Verified