Databricks optimiza el rendimiento de los LLM de código abierto con Automated Prompt Caching
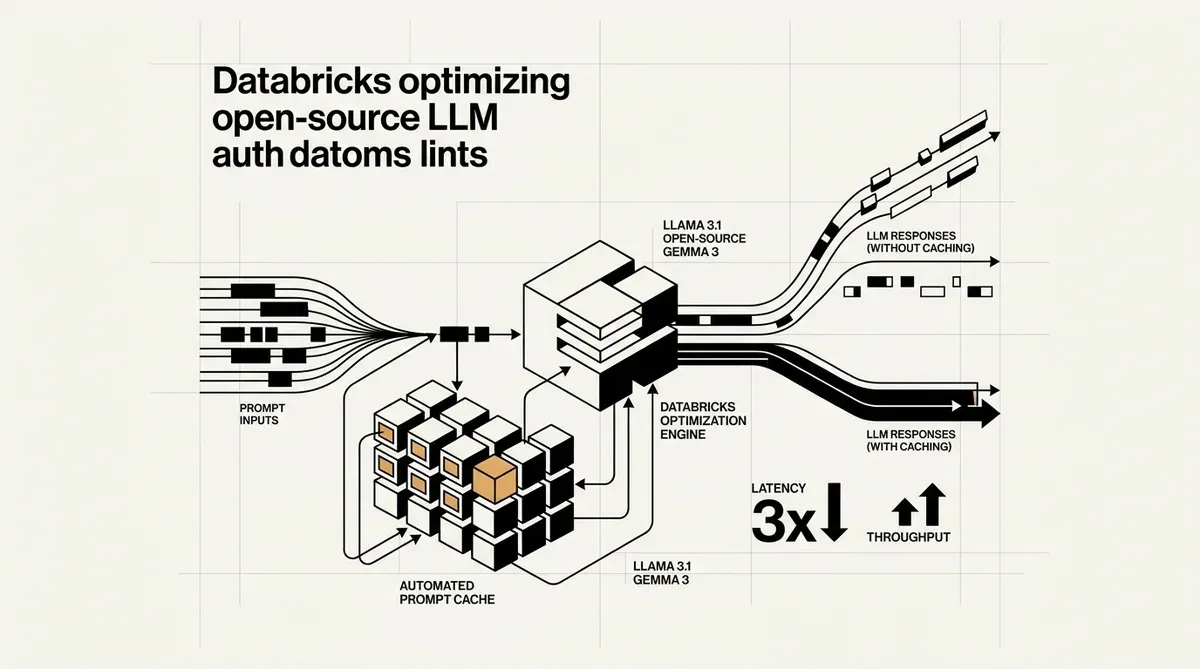
Databricks ha introducido el automated prompt caching para modelos de lenguaje de gran tamaño (LLM) de código abierto, un movimiento diseñado para reducir los costes operativos de desplegar IA a escala. La nueva función, anunciada esta semana, se centra en la alta carga computacional asociada al procesamiento de system prompts extensos y estructuras de consulta repetitivas. Al reutilizar las cachés Key-Value (KV) para prefijos de prompts idénticos, la plataforma elimina la necesidad de ciclos de cómputo redundantes durante la inferencia.
La implementación del automated prompt caching aborda un cuello de botella significativo en los flujos de trabajo de IA empresarial. Muchas organizaciones utilizan system prompts extensos para definir el comportamiento del modelo, las barreras de seguridad (safety guardrails) o el contexto específico del dominio. Anteriormente, estas instrucciones debían procesarse de nuevo para cada consulta individual de los usuarios, lo que provocaba un aumento de la latencia y mayores costes de tokens. Databricks afirmó que sus pruebas de producción interna en modelos GPT-OSS mostraron una reducción de 3 veces en la latencia P50 y un aumento de 2,5 veces en el rendimiento (throughput) general.
Impacto estratégico en el despliegue de IA de código abierto
Esta actualización está disponible tanto para las Foundation Model APIs (FMAPIs) como para los niveles de provisioned throughput en la plataforma Databricks. El aspecto de la automatización es particularmente relevante para los desarrolladores, ya que no requiere configuración manual para activar el prefix caching. El sistema identifica patrones repetitivos en las solicitudes entrantes y almacena los estados calculados en la memoria volátil. Este enfoque garantiza que las mejoras de rendimiento no se produzcan a expensas de la seguridad de los datos, ya que los datos almacenados en caché están aislados y no se guardan en el disco.
La lista de modelos compatibles incluye varias arquitecturas de código abierto de alto perfil. Los usuarios pueden aprovechar esta tecnología con Llama 3.1 (variantes de 8B y 70B), Gemma 3 12B y la familia GPT-OSS en configuraciones de 20B y 120B. Al optimizar la ruta de inferencia para estos modelos, Databricks se posiciona como una alternativa más rentable frente a los proveedores de modelos propietarios para las empresas que prefieren mantener el control sobre sus pesos y datos.
La introducción del automated prompt caching sigue una tendencia general de la industria hacia la optimización de la inferencia. A medida que las empresas pasan de pilotos experimentales a aplicaciones de nivel de producción, el enfoque se ha desplazado del rendimiento bruto del modelo a la economía del despliegue. Databricks pretende capturar este mercado reduciendo la barrera financiera para el uso de modelos de código abierto a gran escala en entornos de alto volumen. La función se está implementando actualmente para todos los usuarios de la plataforma a partir del 23 de mayo de 2026.
Aunque nos esforzamos por la exactitud, bytevyte puede cometer errores. Se aconseja a los usuarios verificar toda la información de forma independiente. No aceptamos ninguna responsabilidad por errores u omisiones.
Sources
Accelerating LLM Inference with Prompt Caching for Open‑Source Models on Databricks
Related Articles
- Databricks: El escalado de memoria para agentes de IA es un eje de diseño clave
- Databricks y OpenAI presentan los GPT-5.5 enterprise AI agents
- Se lanza Amazon Bedrock Advanced Prompt Optimization para agilizar la migración de modelos de AI
✔Human Verified