Databricks otimiza desempenho de LLMs de código aberto com Automated Prompt Caching
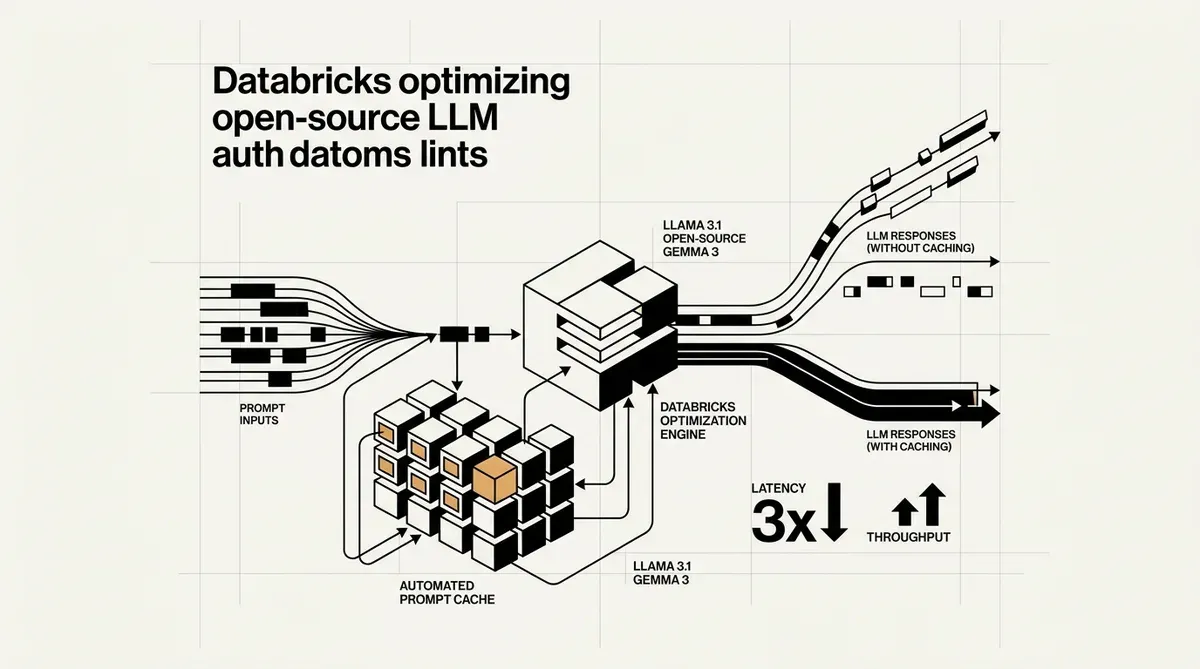
A Databricks introduziu o automated prompt caching para modelos de linguagem de grande porte (LLMs) de código aberto, uma iniciativa projetada para reduzir os custos operacionais de implantação de IA em escala. O novo recurso, anunciado esta semana, visa o alto overhead computacional associado ao processamento de system prompts longos e estruturas de consulta repetitivas. Ao reutilizar caches de Key-Value (KV) para prefixos de prompt idênticos, a plataforma elimina a necessidade de ciclos de computação redundantes durante a inferência.
A implementação do automated prompt caching aborda um gargalo significativo nos fluxos de trabalho de IA corporativa. Muitas organizações utilizam system prompts extensos para definir o comportamento do modelo, diretrizes de segurança (safety guardrails) ou contexto específico do domínio. Anteriormente, essas instruções precisavam ser reprocessadas para cada consulta individual do usuário, levando ao aumento da latência e a custos de tokens mais elevados. A Databricks afirmou que seus testes de produção interna em modelos GPT-OSS mostraram uma redução de 3x na latência P50 e um aumento de 2,5x no throughput geral.
Impacto Estratégico na Implantação de IA de Código Aberto
Esta atualização está disponível tanto para Foundation Model APIs (FMAPIs) quanto para níveis de provisioned throughput na plataforma Databricks. O aspecto da automação é particularmente relevante para desenvolvedores, pois não requer configuração manual para ativar o prefix caching. O sistema identifica padrões repetitivos nas solicitações recebidas e armazena os estados computados em memória volátil. Essa abordagem garante que os ganhos de desempenho não ocorram às custas da segurança dos dados, uma vez que os dados em cache são isolados e não persistidos em disco.
A lista de modelos suportados inclui várias arquiteturas de código aberto de alto perfil. Os usuários podem aproveitar essa tecnologia com Llama 3.1 (variantes 8B e 70B), Gemma 3 12B e a família GPT-OSS nas configurações de 20B e 120B. Ao otimizar o caminho de inferência para esses modelos, a Databricks está se posicionando como uma alternativa mais econômica aos provedores de modelos proprietários para empresas que preferem manter o controle sobre seus pesos e dados.
A introdução do automated prompt caching segue uma tendência mais ampla da indústria em direção à otimização de inferência. À medida que as empresas passam de pilotos experimentais para aplicações de nível de produção, o foco mudou do desempenho bruto do modelo para a economia da implantação. A Databricks visa capturar esse mercado reduzindo a barreira financeira para o uso de modelos de código aberto em larga escala em ambientes de alto volume. O recurso está sendo implementado para todos os usuários da plataforma a partir de 23 de maio de 2026.
Embora nos esforcemos pela precisão, o bytevyte pode cometer erros. Os usuários são aconselhados a verificar todas as informações de forma independente. Não aceitamos qualquer responsabilidade por erros ou omissões.
Sources
Accelerating LLM Inference with Prompt Caching for Open‑Source Models on Databricks
Related Articles
- Databricks e OpenAI Estreiam Agentes de IA Empresariais GPT-5.5
- Amazon Bedrock Advanced Prompt Optimization é lançado para agilizar a migração de modelos de AI
- Databricks: Memory Scaling for AI Agents é o Principal Eixo de Design
✔Human Verified