Databricks optimise les performances des LLM open-source avec l'Automated Prompt Caching
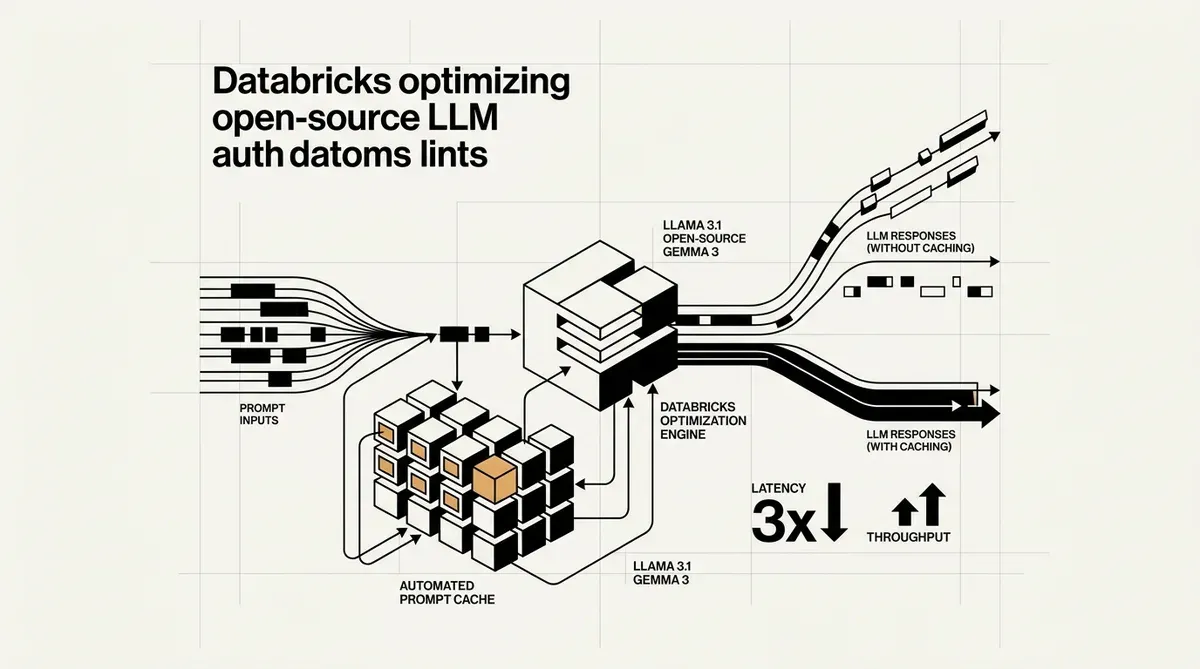
Databricks a introduit l'automated prompt caching pour les grands modèles de langage (LLM) open-source, une initiative conçue pour réduire les coûts opérationnels du déploiement de l'IA à grande échelle. Cette nouvelle fonctionnalité, annoncée cette semaine, cible la charge de calcul élevée associée au traitement des longs prompts système et des structures de requêtes répétitives. En réutilisant les caches Key-Value (KV) pour des préfixes de prompt identiques, la plateforme élimine le besoin de cycles de calcul redondants lors de l'inférence.
L'implémentation de l'automated prompt caching répond à un goulot d'étranglement significatif dans les workflows d'IA en entreprise. De nombreuses organisations utilisent des prompts système étendus pour définir le comportement du modèle, les garde-fous de sécurité ou le contexte spécifique à un domaine. Auparavant, ces instructions devaient être retraitées pour chaque requête utilisateur individuelle, entraînant une latence accrue et des coûts de jetons plus élevés. Databricks a déclaré que ses tests de production internes sur les modèles GPT-OSS ont montré une réduction de 3x de la latence P50 et une augmentation de 2,5x du débit global.
Impact stratégique sur le déploiement de l'IA open-source
Cette mise à jour est disponible à la fois pour les Foundation Model APIs (FMAPIs) et les niveaux de débit provisionnés sur la plateforme Databricks. L'aspect automatisation est particulièrement pertinent pour les développeurs, car il ne nécessite aucune configuration manuelle pour activer le prefix caching. Le système identifie les schémas répétitifs dans les requêtes entrantes et stocke les états calculés dans la mémoire volatile. Cette approche garantit que les gains de performance ne se font pas au détriment de la sécurité des données, car les données mises en cache sont isolées et ne sont pas persistées sur le disque.
La liste des modèles pris en charge comprend plusieurs architectures open-source de premier plan. Les utilisateurs peuvent exploiter cette technologie avec Llama 3.1 (variantes 8B et 70B), Gemma 3 12B, et la famille GPT-OSS dans les configurations 20B et 120B. En optimisant le chemin d'inférence pour ces modèles, Databricks se positionne comme une alternative plus rentable aux fournisseurs de modèles propriétaires pour les entreprises qui préfèrent garder le contrôle sur leurs poids et leurs données.
L'introduction de l'automated prompt caching suit une tendance plus large de l'industrie vers l'optimisation de l'inférence. À mesure que les entreprises passent de pilotes expérimentaux à des applications de production, l'accent s'est déplacé de la performance brute du modèle vers l'économie du déploiement. Databricks vise à capturer ce marché en réduisant la barrière financière à l'utilisation de modèles open-source à grande échelle dans des environnements à haut volume. La fonctionnalité est actuellement en cours de déploiement pour tous les utilisateurs de la plateforme depuis le 23 mai 2026.
Bien que nous nous efforcions d'être précis, bytevyte peut commettre des erreurs. Il est conseillé aux utilisateurs de vérifier toutes les informations de manière indépendante. Nous déclinons toute responsabilité pour les erreurs ou omissions.
Sources
Accelerating LLM Inference with Prompt Caching for Open‑Source Models on Databricks
Related Articles
- Databricks et OpenAI lancent les GPT-5.5 enterprise AI agents
- Lancement d'Amazon Bedrock Advanced Prompt Optimization pour simplifier la migration des modèles d'IA
- Databricks lance les Sketch Functions pour simplifier l'estimation de données à grande échelle
✔Human Verified