Databricks Optimizes Open-Source LLM Performance with Automated Prompt Caching
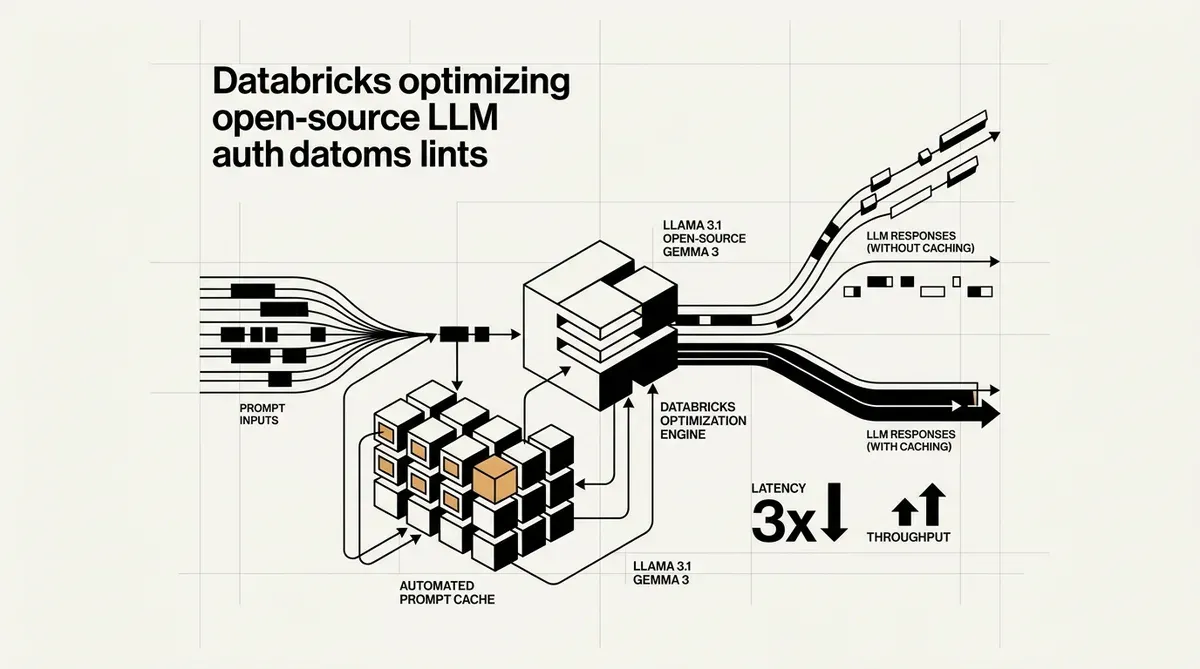
Databricks has introduced automated prompt caching for open-source large language models, a move designed to lower the operational costs of deploying AI at scale. The new feature, announced this week, targets the high computational overhead associated with processing long system prompts and repetitive query structures. By reusing Key-Value (KV) caches for identical prompt prefixes, the platform eliminates the need for redundant compute cycles during inference.
The implementation of automated prompt caching addresses a significant bottleneck in enterprise AI workflows. Many organizations use extensive system prompts to define model behavior, safety guardrails, or domain-specific context. Previously, these instructions had to be reprocessed for every individual user query, leading to increased latency and higher token costs. Databricks stated that its internal production testing on GPT-OSS models showed a 3x reduction in P50 latency and a 2.5x increase in overall throughput.
Strategic Impact on Open-Source AI Deployment
This update is available for both Foundation Model APIs (FMAPIs) and provisioned throughput tiers on the Databricks platform. The automation aspect is particularly relevant for developers, as it requires no manual configuration to activate prefix caching. The system identifies repeating patterns in incoming requests and stores the computed states in volatile memory. This approach ensures that performance gains do not come at the expense of data security, as the cached data is isolated and not persisted to disk.
The list of supported models includes several high-profile open-source architectures. Users can leverage this technology with Llama 3.1 (8B and 70B variants), Gemma 3 12B, and the GPT-OSS family in both 20B and 120B configurations. By optimizing the inference path for these models, Databricks is positioning itself as a more cost-effective alternative to proprietary model providers for enterprises that prefer to maintain control over their weights and data.
The introduction of automated prompt caching follows a broader industry trend toward inference optimization. As companies move from experimental pilots to production-grade applications, the focus has shifted from raw model performance to the economics of deployment. Databricks aims to capture this market by reducing the financial barrier to using large-scale open-source models in high-volume environments. The feature is currently rolling out to all users on the platform as of May 23, 2026.
While we strive for accuracy, bytevyte can make mistakes. Users are advised to verify all information independently. We accept no liability for errors or omissions.
Sources
Accelerating LLM Inference with Prompt Caching for Open‑Source Models on Databricks
AI-generated image.
Related Articles
- Databricks, OpenAI Debut GPT-5.5 Enterprise AI Agents
- Databricks: Memory Scaling for AI Agents is Key Design Axis
- Databricks Launches Sketch Functions to Streamline Large-Scale Data Estimation
✔Human Verified