Databricks ottimizza le prestazioni degli LLM open-source con l'Automated Prompt Caching
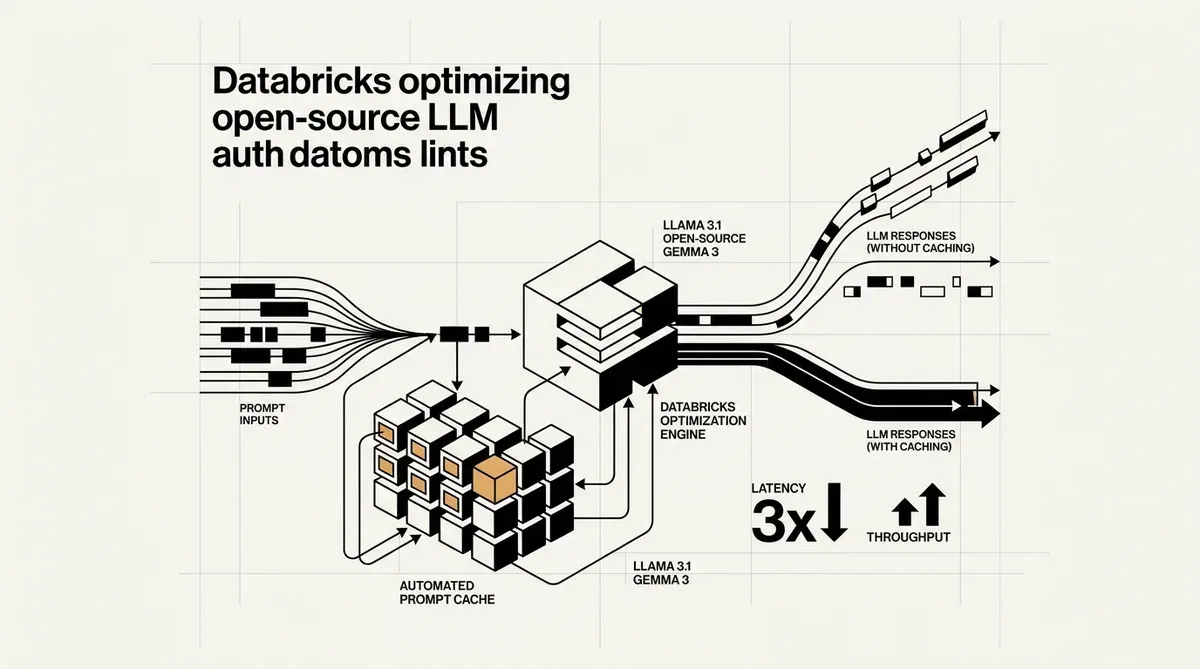
Databricks ha introdotto l'automated prompt caching per i modelli linguistici di grandi dimensioni (LLM) open-source, una mossa progettata per ridurre i costi operativi della distribuzione dell'IA su larga scala. La nuova funzionalità, annunciata questa settimana, punta all'elevato sovraccarico computazionale associato all'elaborazione di lunghi prompt di sistema e strutture di query ripetitive. Riutilizzando le cache Key-Value (KV) per i prefissi dei prompt identici, la piattaforma elimina la necessità di cicli di calcolo ridondanti durante l'inferenza.
L'implementazione dell'automated prompt caching affronta un collo di bottiglia significativo nei flussi di lavoro dell'IA aziendale. Molte organizzazioni utilizzano estesi prompt di sistema per definire il comportamento del modello, i guardrail di sicurezza o il contesto specifico del dominio. In precedenza, queste istruzioni dovevano essere rielaborate per ogni singola query dell'utente, portando a un aumento della latenza e a costi dei token più elevati. Databricks ha dichiarato che i suoi test di produzione interni sui modelli GPT-OSS hanno mostrato una riduzione di 3 volte della latenza P50 e un aumento di 2,5 volte del throughput complessivo.
Impatto strategico sulla distribuzione dell'IA open-source
Questo aggiornamento è disponibile sia per le Foundation Model API (FMAPI) che per i livelli di throughput forniti sulla piattaforma Databricks. L'aspetto dell'automazione è particolarmente rilevante per gli sviluppatori, poiché non richiede alcuna configurazione manuale per attivare il prefix caching. Il sistema identifica i pattern ripetitivi nelle richieste in entrata e memorizza gli stati calcolati nella memoria volatile. Questo approccio garantisce che i guadagni prestazionali non vadano a scapito della sicurezza dei dati, poiché i dati memorizzati nella cache sono isolati e non vengono salvati su disco.
L'elenco dei modelli supportati include diverse architetture open-source di alto profilo. Gli utenti possono sfruttare questa tecnologia con Llama 3.1 (varianti 8B e 70B), Gemma 3 12B e la famiglia GPT-OSS nelle configurazioni da 20B e 120B. Ottimizzando il percorso di inferenza per questi modelli, Databricks si posiziona come un'alternativa più economica ai fornitori di modelli proprietari per le aziende che preferiscono mantenere il controllo sui propri pesi e dati.
L'introduzione dell'automated prompt caching segue una tendenza più ampia del settore verso l'ottimizzazione dell'inferenza. Man mano che le aziende passano dai progetti pilota sperimentali alle applicazioni di livello produttivo, l'attenzione si è spostata dalle prestazioni grezze del modello all'economia della distribuzione. Databricks mira a conquistare questo mercato riducendo la barriera finanziaria all'uso di modelli open-source su larga scala in ambienti ad alto volume. La funzione è attualmente in fase di rilascio per tutti gli utenti della piattaforma a partire dal 23 maggio 2026.
Sebbene ci impegniamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Sources
Accelerating LLM Inference with Prompt Caching for Open‑Source Models on Databricks
Related Articles
- Lancio di Amazon Bedrock Advanced Prompt Optimization per semplificare la migrazione dei modelli AI
- Databricks e OpenAI lanciano gli agenti AI GPT-5.5 Enterprise
- Databricks: Memory Scaling for AI Agents è un asse di progettazione chiave
✔Human Verified