Google and NVIDIA Launch DiffusionGemma to Deliver 4x Faster Parallel Text Generation
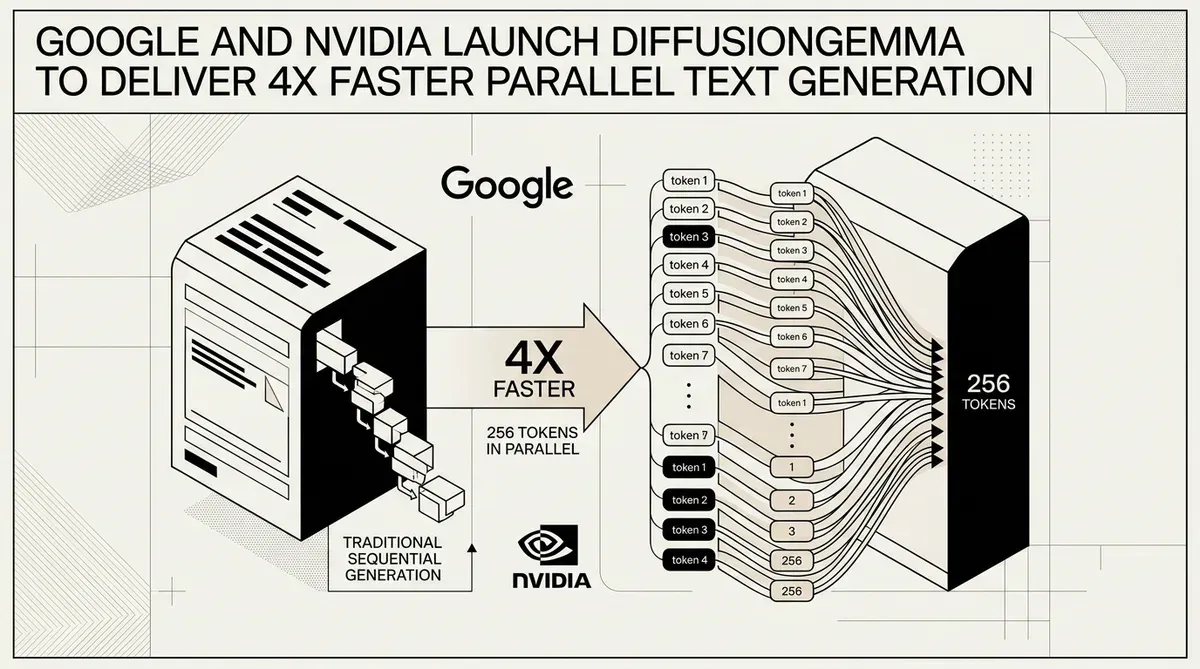
Google and NVIDIA have unveiled DiffusionGemma, an experimental open model that utilizes a novel diffusion-based architecture to accelerate text generation by up to four times compared to traditional autoregressive methods. Released on June 10, 2026, the model shifts the primary bottleneck of large language model (LLM) inference from memory bandwidth to raw compute power. This architectural change allows DiffusionGemma to generate 256 tokens in parallel during a single forward pass, reaching speeds of over 1,000 tokens per second on NVIDIA H100 hardware.
The release addresses a fundamental limitation in current AI systems where tokens are typically predicted one by one. By integrating a specialized diffusion head onto the Gemma 4 family foundation, Google DeepMind has created a system capable of block-based generation. This approach is particularly effective for non-linear tasks such as code infilling and complex document editing, where bi-directional attention provides a performance advantage over standard left-to-right processing.
Technical Specifications and Performance
DiffusionGemma is built on a 26B Mixture of Experts (MoE) architecture, though it only utilizes 3.8B active parameters during inference to maintain efficiency. The model is available under an Apache 2.0 open-weight license, making it accessible for enterprise and research applications. For local deployments, the VRAM requirement sits at approximately 18GB when using quantization, allowing it to run on high-end consumer hardware.
NVIDIA has provided day-zero optimization for the model, ensuring it leverages Tensor Cores for the dense parallel mathematics required by the diffusion process. Performance benchmarks shared by the companies indicate the following output speeds:
- NVIDIA H100: 1,000+ tokens per second.
- NVIDIA RTX 5090: 700+ tokens per second.
The model also supports NVFP4 kernels on Blackwell and Hopper architectures, further reducing the computational overhead for real-time applications.
Strategic Implications for Enterprise AI
The introduction of DiffusionGemma signals a shift toward low-latency agentic loops and highly interactive local assistants. For decision-makers, the ability to generate text at these speeds without relying on massive cloud-based memory bandwidth opens new possibilities for edge computing and private data processing. The parallel nature of the model makes it a strong candidate for workflows that require rapid iteration, such as real-time code generation or automated content refactoring.
By moving the bottleneck to compute, Google and NVIDIA are aligning model architecture with the strengths of modern GPU hardware. This development suggests that future LLM scaling may focus as much on parallel generation techniques as it does on parameter count. Developers can already access the model through platforms like Hugging Face Transformers, vLLM, and Unsloth to begin integrating these high-speed capabilities into their existing AI stacks.
While we strive for accuracy, bytevyte can make mistakes. Users are advised to verify all information independently. We accept no liability for errors or omissions.
Sources
DiffusionGemma: 4x faster text generation
NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
AI-generated image.
Related Articles
- NVIDIA Unveils Nemotron-Labs Diffusion for High-Speed Parallel Text Generation
- Google Accelerates AI Inference with Gemma 4 Multi-Token Prediction Drafters
- NVIDIA Unveils Nemotron 3 Nano Omni to Streamline Multimodal AI Workflows
✔Human Verified