Google et NVIDIA lancent DiffusionGemma pour une génération de texte parallèle 4x plus rapide
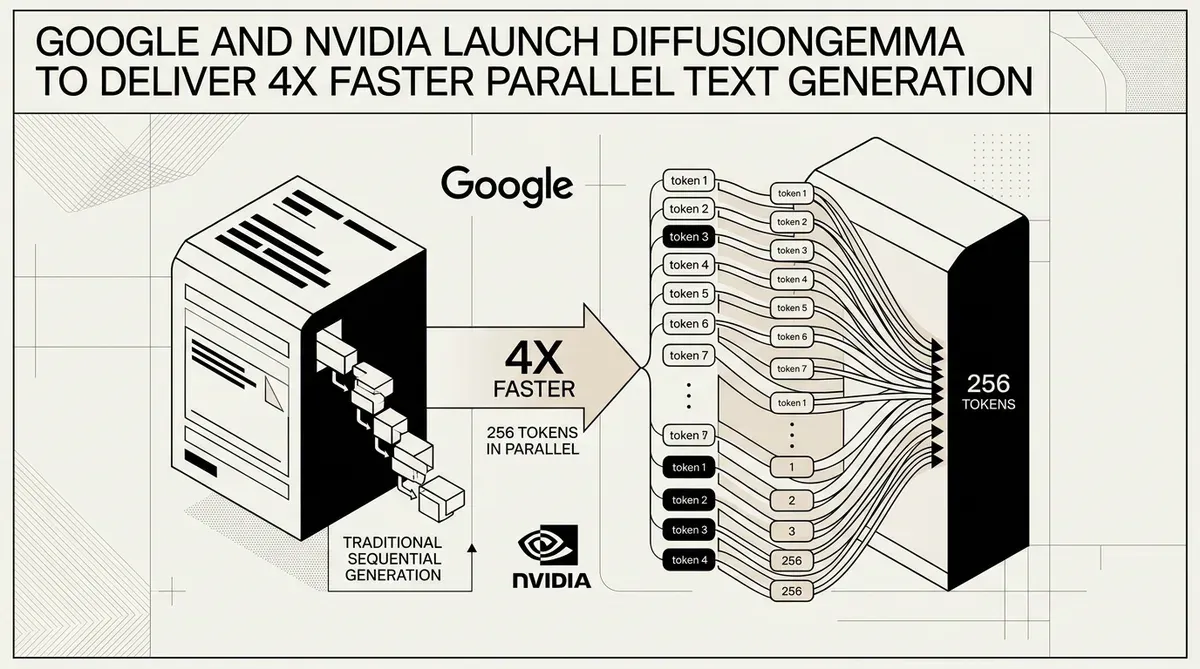
Google et NVIDIA ont dévoilé DiffusionGemma, un modèle ouvert expérimental qui utilise une architecture novatrice basée sur la diffusion pour accélérer la génération de texte jusqu'à quatre fois par rapport aux méthodes autorégressives traditionnelles. Publié le 10 juin 2026, le modèle déplace le goulot d'étranglement principal de l'inférence des grands modèles de langage (LLM) de la bande passante mémoire vers la puissance de calcul brute. Ce changement architectural permet à DiffusionGemma de générer 256 jetons en parallèle lors d'une seule passe directe, atteignant des vitesses de plus de 1 000 jetons par seconde sur le matériel NVIDIA H100.
Cette version répond à une limitation fondamentale des systèmes d'IA actuels où les jetons sont généralement prédits un par un. En intégrant une tête de diffusion spécialisée sur la fondation de la famille Gemma 4, Google DeepMind a créé un système capable de génération par blocs. Cette approche est particulièrement efficace pour les tâches non linéaires telles que le remplissage de code (code infilling) et l'édition de documents complexes, où l'attention bidirectionnelle offre un avantage de performance par rapport au traitement standard de gauche à droite.
Spécifications techniques et performances
DiffusionGemma est construit sur une architecture 26B Mixture of Experts (MoE), bien qu'il n'utilise que 3,8B de paramètres actifs lors de l'inférence pour maintenir l'efficacité. Le modèle est disponible sous une licence de poids ouverts Apache 2.0, le rendant accessible pour les applications d'entreprise et de recherche. Pour les déploiements locaux, l'exigence de VRAM se situe à environ 18 Go lors de l'utilisation de la quantification, ce qui lui permet de fonctionner sur du matériel grand public haut de gamme.
NVIDIA a fourni une optimisation dès le premier jour pour le modèle, garantissant qu'il exploite les Tensor Cores pour les calculs parallèles denses requis par le processus de diffusion. Les benchmarks de performance partagés par les entreprises indiquent les vitesses de sortie suivantes :
- NVIDIA H100 : plus de 1 000 jetons par seconde.
- NVIDIA RTX 5090 : plus de 700 jetons par seconde.
Le modèle prend également en charge les noyaux NVFP4 sur les architectures Blackwell et Hopper, réduisant davantage la charge de calcul pour les applications en temps réel.
Implications stratégiques pour l'IA en entreprise
L'introduction de DiffusionGemma signale une transition vers des boucles agentiques à faible latence et des assistants locaux hautement interactifs. Pour les décideurs, la capacité de générer du texte à ces vitesses sans dépendre d'une bande passante mémoire massive dans le cloud ouvre de nouvelles possibilités pour l'edge computing et le traitement de données privées. La nature parallèle du modèle en fait un candidat solide pour les flux de travail nécessitant une itération rapide, comme la génération de code en temps réel ou la restructuration automatisée de contenu.
En déplaçant le goulot d'étranglement vers le calcul, Google et NVIDIA alignent l'architecture du modèle avec les forces du matériel GPU moderne. Ce développement suggère que la future mise à l'échelle des LLM pourrait se concentrer autant sur les techniques de génération parallèle que sur le nombre de paramètres. Les développeurs peuvent déjà accéder au modèle via des plateformes telles que Hugging Face Transformers, vLLM et Unsloth pour commencer à intégrer ces capacités à haute vitesse dans leurs piles technologiques IA existantes.
Bien que nous nous efforcions d'être précis, bytevyte peut commettre des erreurs. Il est conseillé aux utilisateurs de vérifier toutes les informations de manière indépendante. Nous déclinons toute responsabilité pour les erreurs ou omissions.
Sources
DiffusionGemma: 4x faster text generation
NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
Related Articles
- NVIDIA dévoile Nemotron-Labs Diffusion pour une génération de texte parallèle à haute vitesse
- Google accélère l'inférence IA avec les drafters Gemma 4 Multi-Token Prediction
- NVIDIA dévoile Nemotron 3 Nano Omni pour simplifier les workflows d'IA multimodale
✔Human Verified