Google und NVIDIA veröffentlichen DiffusionGemma für 4x schnellere parallele Textgenerierung
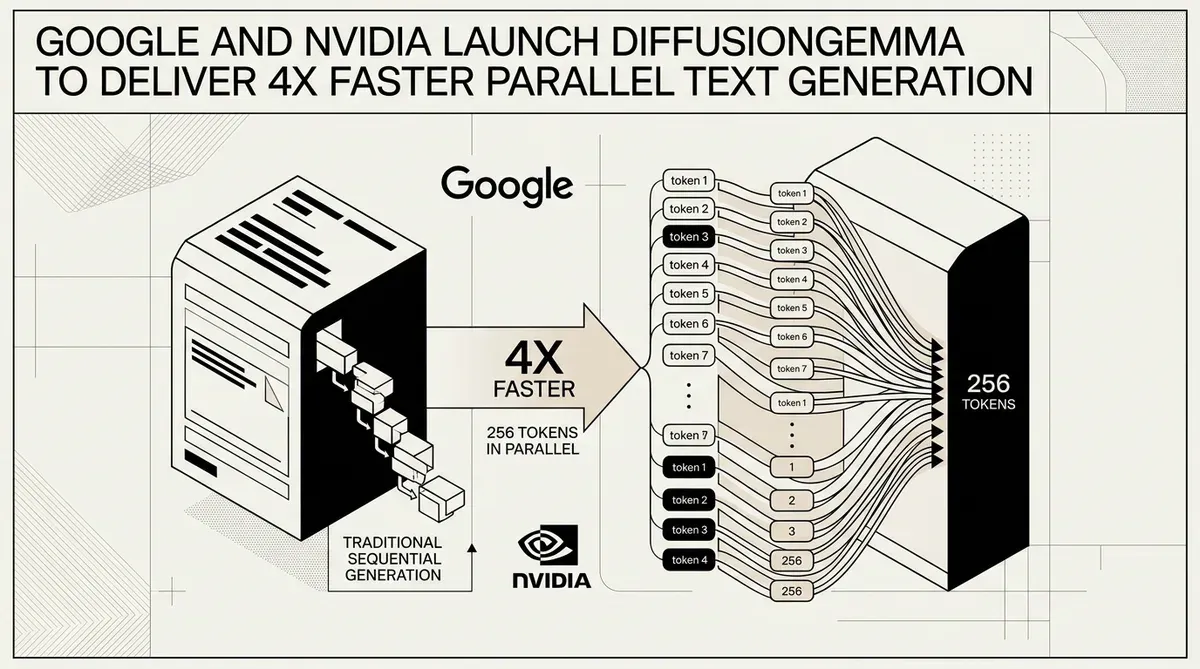
Google und NVIDIA haben DiffusionGemma vorgestellt, ein experimentelles offenes Modell, das eine neuartige diffusionsbasierte Architektur nutzt, um die Textgenerierung im Vergleich zu herkömmlichen autoregressiven Methoden um das Vierfache zu beschleunigen. Das am 10. Juni 2026 veröffentlichte Modell verschiebt den primären Flaschenhals der Inferenz von Large Language Models (LLM) von der Speicherbandbreite hin zur reinen Rechenleistung. Diese architektonische Änderung ermöglicht es DiffusionGemma, 256 Token parallel in einem einzigen Forward Pass zu generieren und dabei Geschwindigkeiten von über 1.000 Token pro Sekunde auf NVIDIA H100-Hardware zu erreichen.
Die Veröffentlichung adressiert eine grundlegende Einschränkung aktueller KI-Systeme, bei denen Token normalerweise nacheinander vorhergesagt werden. Durch die Integration eines spezialisierten Diffusion-Heads auf der Basis der Gemma 4-Familie hat Google DeepMind ein System geschaffen, das zur blockbasierten Generierung fähig ist. Dieser Ansatz ist besonders effektiv für nicht-lineare Aufgaben wie Code Infilling und komplexe Dokumentenbearbeitung, bei denen bidirektionale Attention einen Leistungsvorteil gegenüber der standardmäßigen Links-nach-Rechts-Verarbeitung bietet.
Technische Spezifikationen und Performance
DiffusionGemma basiert auf einer 26B Mixture of Experts (MoE) Architektur, nutzt jedoch nur 3,8B aktive Parameter während der Inferenz, um die Effizienz zu wahren. Das Modell ist unter einer Apache 2.0 Open-Weight-Lizenz verfügbar, was es für Unternehmens- und Forschungsanwendungen zugänglich macht. Für lokale Deployments liegt der VRAM-Bedarf bei Verwendung von Quantisierung bei etwa 18 GB, sodass es auf High-End-Consumer-Hardware ausgeführt werden kann.
NVIDIA hat eine Day-Zero-Optimierung für das Modell bereitgestellt und stellt sicher, dass es Tensor Cores für die dichte parallele Mathematik nutzt, die für den Diffusionsprozess erforderlich ist. Die von den Unternehmen geteilten Performance-Benchmarks zeigen die folgenden Ausgabegeschwindigkeiten:
- NVIDIA H100: 1.000+ Token pro Sekunde.
- NVIDIA RTX 5090: 700+ Token pro Sekunde.
Das Modell unterstützt zudem NVFP4-Kernel auf Blackwell- und Hopper-Architekturen, was den Rechenaufwand für Echtzeitanwendungen weiter reduziert.
Strategische Auswirkungen für Enterprise AI
Die Einführung von DiffusionGemma signalisiert einen Wandel hin zu Low-Latency Agentic Loops und hochgradig interaktiven lokalen Assistenten. Für Entscheidungsträger eröffnet die Fähigkeit, Texte in dieser Geschwindigkeit zu generieren, ohne auf massive cloudbasierte Speicherbandbreite angewiesen zu sein, neue Möglichkeiten für Edge Computing und private Datenverarbeitung. Die parallele Natur des Modells macht es zu einem starken Kandidaten für Workflows, die eine schnelle Iteration erfordern, wie etwa Echtzeit-Codegenerierung oder automatisiertes Content-Refactoring.
Indem sie den Flaschenhals zur Rechenleistung verschieben, richten Google und NVIDIA die Modellarchitektur an den Stärken moderner GPU-Hardware aus. Diese Entwicklung deutet darauf hin, dass sich die künftige Skalierung von LLMs ebenso sehr auf parallele Generierungstechniken wie auf die Parameteranzahl konzentrieren könnte. Entwickler können bereits über Plattformen wie Hugging Face Transformers, vLLM und Unsloth auf das Modell zugreifen, um diese Hochgeschwindigkeitsfunktionen in ihre bestehenden KI-Stacks zu integrieren.
Obwohl wir um Genauigkeit bemüht sind, kann bytevyte Fehler machen. Benutzern wird empfohlen, alle Informationen unabhängig zu überprüfen. Wir übernehmen keine Haftung für Fehler oder Auslassungen.
Sources
DiffusionGemma: 4x faster text generation
NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
Related Articles
- NVIDIA enthüllt Nemotron-Labs Diffusion für parallele Textgenerierung in Hochgeschwindigkeit
- Google beschleunigt AI-Inference mit Gemma 4 Multi-Token Prediction Drafters
- NVIDIA enthüllt Nemotron 3 Nano Omni zur Optimierung multimodaler KI-Workflows
✔Human Verified