NVIDIA e Hugging Face Avançam no Treinamento de LLM com Task-Seeded Synthetic Data Generation
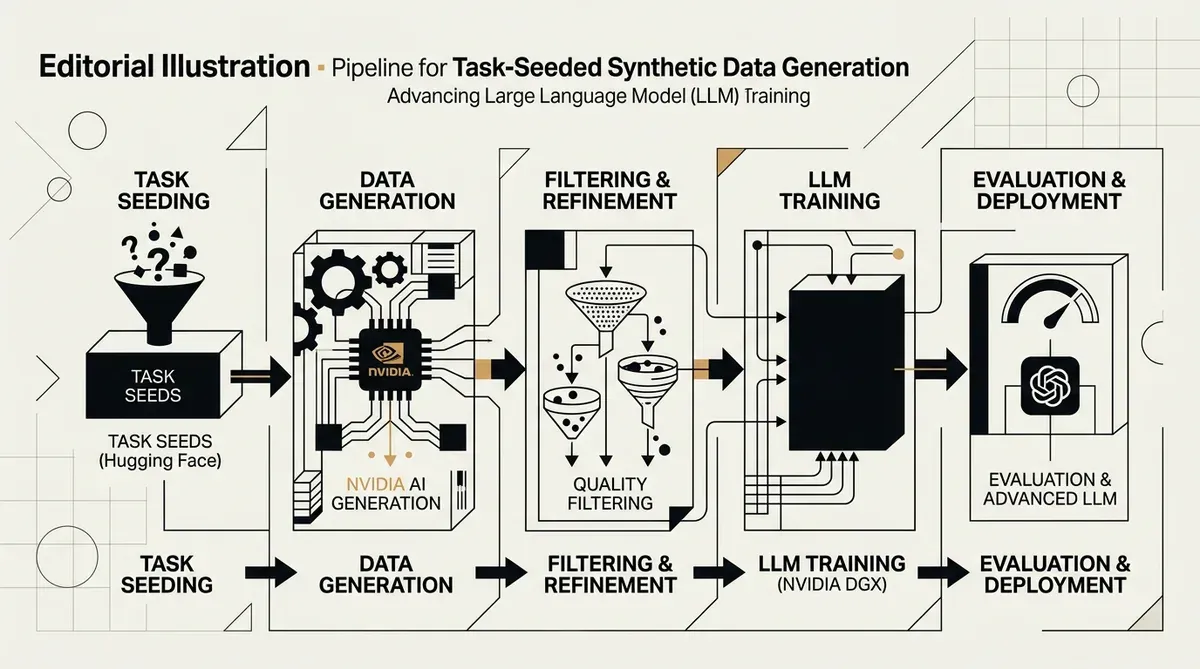
NVIDIA e Hugging Face introduziram uma nova metodologia para task-seeded synthetic data generation, um framework projetado para melhorar o pré-treinamento de grandes modelos de linguagem através da criação de conjuntos de treinamento estruturados e de alta qualidade. Esta pesquisa colaborativa aborda a crescente escassez de dados gerados por humanos ao usar capacidades de tarefas existentes como sementes para produzir pares complexos de Q&A sintéticos. O sistema visa ir além da simples replicação de dados, focando, em vez disso, no aprendizado por transferência para impulsionar o desempenho do modelo em diversos domínios.
O processo de task-seeded synthetic data generation segue um pipeline de cinco estágios para garantir a qualidade e a utilidade do resultado. Este fluxo de trabalho começa com a coleta de sementes, seguida pela normalização de registros e geração de exemplos. Os estágios finais envolvem o enriquecimento de respostas, onde traços de raciocínio são adicionados aos dados, e uma fase de filtragem para remover entradas de baixa qualidade. Ao usar 70 tarefas e 700 subtarefas do lm-eval-harness como sementes, os pesquisadores criaram uma base diversificada para gerar conteúdo sintético que inclui tanto contexto quanto etapas lógicas.
Impacto Estratégico no Escalonamento de Modelos
A eficácia desta abordagem foi testada usando o modelo Nemotron-3 Nano em um experimento de continuação de 100B tokens. A NVIDIA relatou que os dados sintéticos estruturados melhoraram o desempenho do modelo mesmo em áreas que não faziam parte das tarefas sementes originais. Isso sugere que o método é eficaz para melhorias de capacidade geral, em vez de apenas memorizar conjuntos de dados específicos. Para líderes empresariais, isso representa uma mudança na forma como modelos de fronteira podem ser escalonados de forma eficiente sem depender exclusivamente de dados curados por humanos, que são cada vez mais caros ou raros.
Ao enriquecer os dados sintéticos com traços de raciocínio, o framework fornece aos modelos as etapas lógicas por trás de uma resposta, o que é um fator-chave no desenvolvimento de capacidades avançadas de raciocínio. Este desenvolvimento é particularmente relevante para organizações que constroem modelos especializados onde dados de alta qualidade específicos do domínio são limitados. A colaboração entre NVIDIA e Hugging Face destaca uma tendência para pipelines de dados sintéticos mais sofisticados que priorizam a integridade estrutural e a profundidade lógica em vez do volume puro.
A partir de junho de 2026, a integração de tais técnicas de dados sintéticos está se tornando uma parte padrão do ciclo de vida de desenvolvimento de IA. A capacidade de gerar material de treinamento de alta fidelidade a partir de um conjunto limitado de sementes de capacidade permite melhorias de modelo mais direcionadas. A NVIDIA e a Hugging Face disponibilizaram os detalhes técnicos deste aprofundamento para a comunidade de pesquisa, sinalizando um impulso para uma adoção mais ampla da geração de dados sintéticos estruturados na indústria.
Embora nos esforcemos pela precisão, o bytevyte pode cometer erros. Os usuários são aconselhados a verificar todas as informações de forma independente. Não aceitamos qualquer responsabilidade por erros ou omissões.
Sources
Task-Seeded Synthetic Q&A Generation for Nemotron Pretraining
Related Articles
- NVIDIA Unveils Physical AI Agent Skills to Accelerate Autonomous System Training
- NVIDIA e HuggingFace Usam Personas Sintéticas para Localizar Korean AI agents
- NVIDIA revela Nemotron-Labs Diffusion para geração paralela de texto em alta velocidade
✔Human Verified