NVIDIA et Hugging Face font progresser l'entraînement des LLM avec la task-seeded synthetic data generation
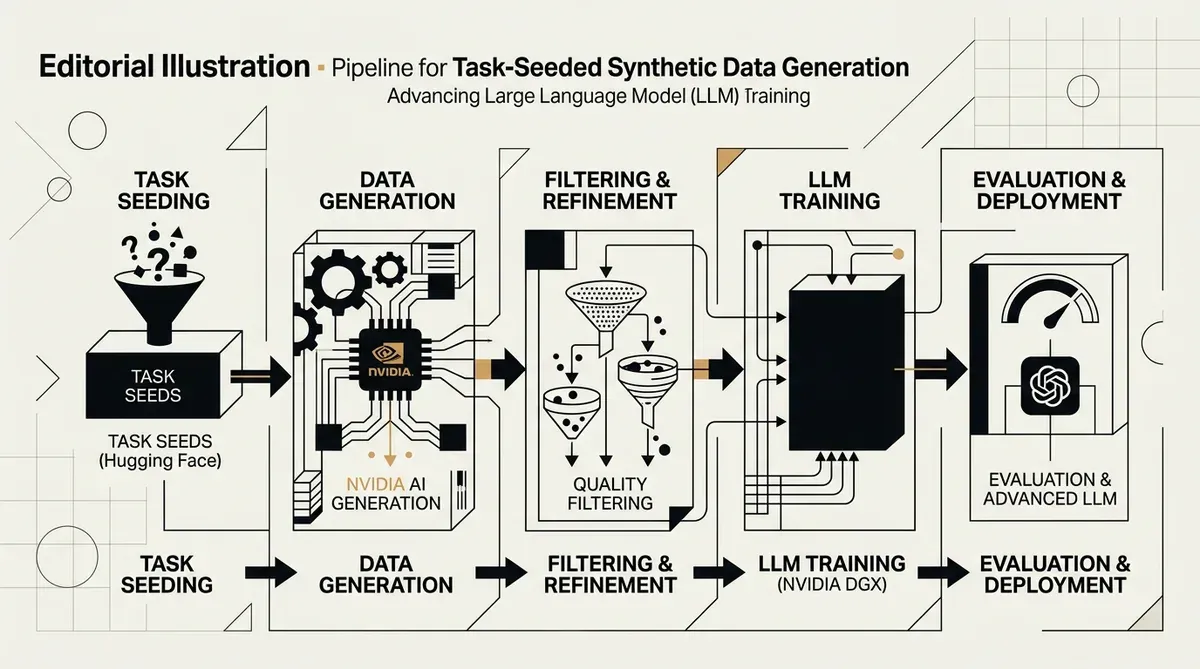
NVIDIA et Hugging Face ont introduit une nouvelle méthodologie pour la task-seeded synthetic data generation, un framework conçu pour améliorer le pré-entraînement des grands modèles de langage en créant des ensembles d'entraînement structurés et de haute qualité. Cette recherche collaborative répond à la rareté croissante des données générées par l'homme en utilisant les capacités de tâches existantes comme « graines » (seeds) pour produire des paires de Q&A synthétiques complexes. Le système vise à aller au-delà de la simple réplication de données, en se concentrant plutôt sur l'apprentissage par transfert pour booster les performances des modèles dans divers domaines.
Le processus de task-seeded synthetic data generation suit un pipeline en cinq étapes pour garantir la qualité et l'utilité des résultats. Ce flux de travail commence par la collecte de graines, suivie de la normalisation des enregistrements et de la génération d'exemples. Les étapes finales impliquent l'enrichissement des réponses, où des traces de raisonnement sont ajoutées aux données, et une phase de filtrage pour éliminer les entrées de faible qualité. En utilisant 70 tâches et 700 sous-tâches du lm-eval-harness comme graines, les chercheurs ont créé une base diversifiée pour générer du contenu synthétique incluant à la fois du contexte et des étapes logiques.
Impact stratégique sur la mise à l'échelle des modèles
L'efficacité de cette approche a été testée à l'aide du modèle Nemotron-3 Nano dans une expérience de continuation de 100 milliards de tokens. NVIDIA a rapporté que les données synthétiques structurées ont amélioré les performances du modèle, même dans des domaines qui ne faisaient pas partie des tâches initiales. Cela suggère que la méthode est efficace pour l'amélioration des capacités générales plutôt que pour la simple mémorisation de jeux de données spécifiques. Pour les dirigeants d'entreprise, il s'agit d'un changement dans la manière dont les modèles de pointe peuvent être mis à l'échelle efficacement sans dépendre uniquement de données organisées par l'homme, de plus en plus coûteuses ou rares.
En enrichissant les données synthétiques avec des traces de raisonnement, le framework fournit aux modèles les étapes logiques derrière une réponse, ce qui est un facteur clé dans le développement de capacités de raisonnement avancées. Ce développement est particulièrement pertinent pour les organisations qui construisent des modèles spécialisés où les données de haute qualité spécifiques à un domaine sont limitées. La collaboration entre NVIDIA et Hugging Face souligne une tendance vers des pipelines de données synthétiques plus sophistiqués qui privilégient l'intégrité structurelle et la profondeur logique plutôt que le simple volume.
En juin 2026, l'intégration de telles techniques de données synthétiques devient une étape standard du cycle de vie du développement de l'IA. La capacité à générer du matériel d'entraînement de haute fidélité à partir d'un ensemble limité de graines de capacités permet des améliorations de modèles plus ciblées. NVIDIA et Hugging Face ont mis les détails techniques de cette analyse approfondie à la disposition de la communauté de recherche, signalant une poussée pour une adoption plus large de la génération de données synthétiques structurées dans l'industrie.
Bien que nous nous efforcions d'être précis, bytevyte peut faire des erreurs. Il est conseillé aux utilisateurs de vérifier toutes les informations de manière indépendante. Nous déclinons toute responsabilité pour les erreurs ou omissions.
Sources
Task-Seeded Synthetic Q&A Generation for Nemotron Pretraining
Related Articles
- NVIDIA dévoile des physical AI agent skills pour accélérer l'entraînement des systèmes autonomes
- NVIDIA dévoile Nemotron-Labs Diffusion pour une génération de texte parallèle à haute vitesse
- NVIDIA et HuggingFace utilisent des personas synthétiques pour localiser les Korean AI agents
✔Human Verified