NVIDIA porta Nemotron 3 Ultra su AWS per potenziare agenti autonomi ad alta efficienza
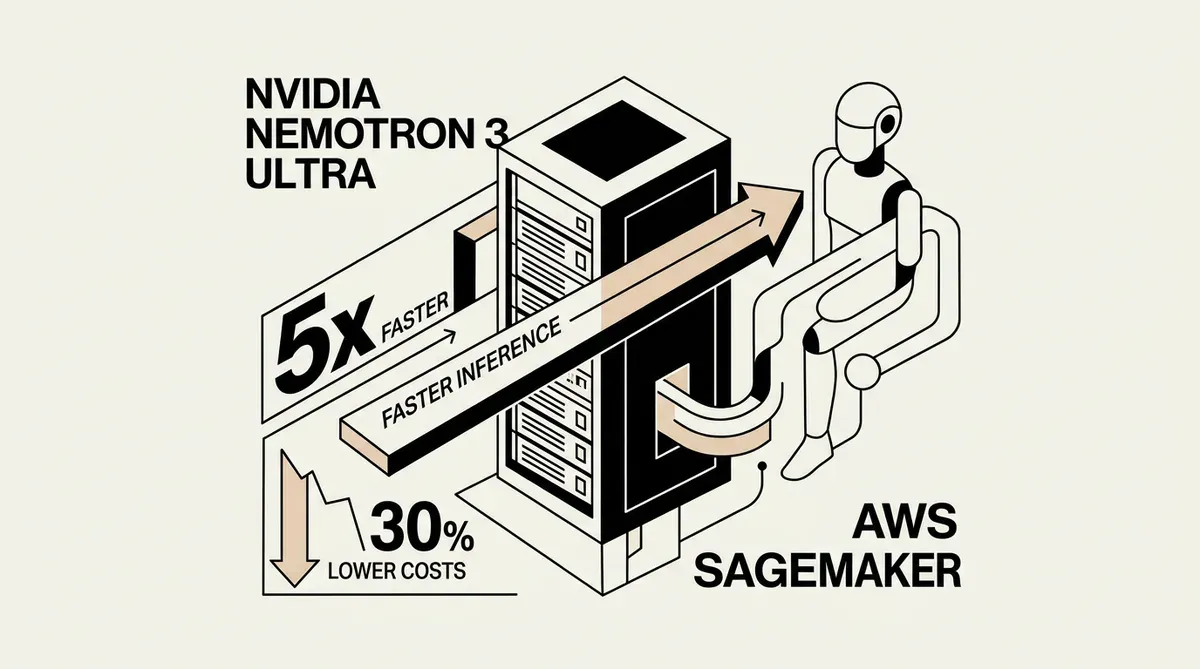
NVIDIA ha lanciato Nemotron 3 Ultra su Amazon SageMaker JumpStart, introducendo un modello ad alta efficienza progettato specificamente per agenti autonomi a lunga esecuzione e ragionamento complesso. Questo rilascio, annunciato questa settimana, rappresenta un cambiamento significativo verso l'AI agentica offrendo un modello da 550 miliardi di parametri che mantiene i costi operativi di sistemi molto più piccoli. La piattaforma supporta una context length massiccia di 1 milione di token, consentendo alle imprese di elaborare vasti dataset all'interno di una singola finestra di ragionamento.
Il modello Nemotron 3 Ultra utilizza un'architettura ibrida che bilancia 550 miliardi di parametri totali con 55 miliardi di parametri attivi. Questo design permette al sistema di ottenere un'inferenza 5 volte più veloce per i carichi di lavoro agentici, riducendo al contempo i costi di hosting del 30% rispetto ai modelli densi tradizionali. Ottimizzando per il formato NVFP4, NVIDIA e AWS hanno snellito il processo di implementazione per le aziende che richiedono capacità di ragionamento multi-step ad alto throughput senza il tipico sovraccarico hardware degli LLM su larga scala.
Impatto strategico dell'efficienza dell'AI agentica
Per i decision-maker, l'arrivo di Nemotron 3 Ultra su Amazon SageMaker JumpStart affronta la barriera principale per l'implementazione di agenti autonomi: il rapporto costo-prestazioni. I modelli densi standard diventano spesso proibitivi in termini di costi quando vengono incaricati dell'elaborazione continua e iterativa richiesta dagli agenti autonomi. L'approccio ibrido di NVIDIA mitiga questo problema attivando solo una frazione dei parametri totali per ogni task, garantendo che il ragionamento complesso non porti a incrementi esponenziali della spesa computazionale.
Insieme ai guadagni prestazionali, NVIDIA sta affrontando il lato della governance dell'AI aziendale con il rilascio di Nemotron 3.5 Content Safety. Questo modello da 4 miliardi di parametri, costruito sulla base di Google Gemma 3, fornisce filtri di sicurezza multimodali e multilingue in 12 lingue. Una caratteristica chiave è la modalità THINK, che offre un ragionamento auditable e passo-passo per i verdetti di sicurezza. Questa trasparenza consente alle organizzazioni di applicare policy di sicurezza personalizzate che corrispondono a specifici requisiti aziendali o normativi, invece di affidarsi a filtri di sicurezza black-box.
L'integrazione di questi modelli nell'ecosistema AWS semplifica il percorso dallo sviluppo alla produzione. Con il deployment one-click ora disponibile, le aziende possono integrare protocolli di sicurezza avanzati e ragionamento ad alta efficienza nei loro flussi di lavoro cloud esistenti. Mentre le imprese passano da semplici chatbot ad agenti autonomi sofisticati, la combinazione di inferenza ad alta velocità e framework di sicurezza auditable diventerà probabilmente lo standard per le applicazioni AI di livello production.
Sebbene ci impegniamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Sources
NVIDIA Nemotron 3 Ultra now available on Amazon SageMaker JumpStart
Nemotron 3.5 Content Safety: Customizable Multimodal Safety for Global Enterprise AI
Related Articles
- Amazon Bedrock integra OpenAI GPT OSS e NVIDIA Nemotron per diversificare le opzioni AI aziendali
- AWS integra le GPU NVIDIA Blackwell in SageMaker con le nuove istanze G7e
- NVIDIA presenta Nemotron 3 Nano Omni per ottimizzare i flussi di lavoro AI multimodali
✔Human Verified