NVIDIA und Hugging Face treiben LLM-Training mit Task-Seeded Synthetic Data Generation voran
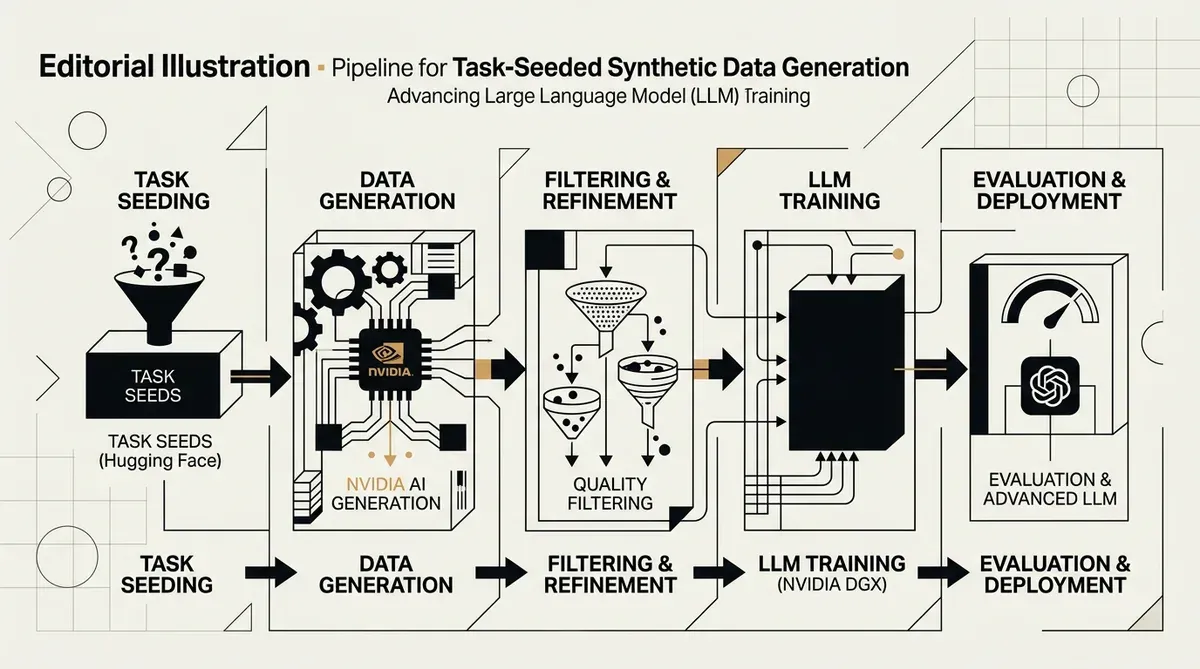
NVIDIA und Hugging Face haben eine neue Methodik für task-seeded synthetic data generation vorgestellt – ein Framework, das darauf ausgelegt ist, das Pretraining von Large Language Models durch die Erstellung hochwertiger, strukturierter Trainingssets zu verbessern. Diese gemeinschaftliche Forschung adressiert den wachsenden Mangel an von Menschen generierten Daten, indem bestehende Aufgabenkapazitäten als Seeds genutzt werden, um komplexe synthetische Q&A-Paare zu erzeugen. Das System zielt darauf ab, über die einfache Datenreplikation hinauszugehen und konzentriert sich stattdessen auf Transfer Learning, um die Modellleistung über verschiedene Domänen hinweg zu steigern.
Der task-seeded synthetic data generation-Prozess folgt einer fünfstufigen Pipeline, um die Qualität und den Nutzen der Ergebnisse sicherzustellen. Dieser Workflow beginnt mit der Seed-Sammlung, gefolgt von der Datensatz-Normalisierung und der Beispielgenerierung. Die letzten Phasen umfassen die Anreicherung der Antworten, bei der Reasoning Traces zu den Daten hinzugefügt werden, sowie eine Filterphase zur Entfernung minderwertiger Einträge. Durch die Verwendung von 70 Aufgaben und 700 Unteraufgaben aus dem lm-eval-harness als Seeds haben die Forscher eine vielfältige Grundlage für die Generierung synthetischer Inhalte geschaffen, die sowohl Kontext als auch logische Schritte enthalten.
Strategische Auswirkungen auf die Modellskalierung
Die Wirksamkeit dieses Ansatzes wurde mit dem Nemotron-3 Nano-Modell in einem 100B-Token-Fortsetzungsexperiment getestet. NVIDIA berichtete, dass die strukturierten synthetischen Daten die Leistung des Modells sogar in Bereichen verbesserten, die nicht Teil der ursprünglichen Seed-Aufgaben waren. Dies deutet darauf hin, dass die Methode effektiv für allgemeine Fähigkeitsverbesserungen ist, anstatt nur spezifische Datensätze auswendig zu lernen. Für Unternehmensleiter stellt dies einen Wendepunkt dar, wie Frontier-Modelle effizient skaliert werden können, ohne sich ausschließlich auf zunehmend teure oder seltene, von Menschen kuratierte Daten verlassen zu müssen.
Durch die Anreicherung synthetischer Daten mit Reasoning Traces liefert das Framework den Modellen die logischen Schritte hinter einer Antwort, was ein Schlüsselfaktor für die Entwicklung fortgeschrittener Denkfähigkeiten ist. Diese Entwicklung ist besonders relevant für Organisationen, die spezialisierte Modelle entwickeln, bei denen hochwertige domänenspezifische Daten begrenzt sind. Die Zusammenarbeit zwischen NVIDIA und Hugging Face unterstreicht einen Trend hin zu anspruchsvolleren synthetischen Daten-Pipelines, die strukturelle Integrität und logische Tiefe über das reine Volumen stellen.
Stand Juni 2026 wird die Integration solcher synthetischen Datentechniken zu einem Standardbestandteil des KI-Entwicklungszyklus. Die Fähigkeit, hochpräzises Trainingsmaterial aus einem begrenzten Satz von Capability-Seeds zu generieren, ermöglicht gezieltere Modellverbesserungen. NVIDIA und Hugging Face haben die technischen Details dieses Deep-Dives der Forschungsgemeinschaft zugänglich gemacht und signalisieren damit einen Vorstoß für eine breitere Akzeptanz der strukturierten synthetischen Datengenerierung in der Branche.
Obwohl wir uns um Genauigkeit bemühen, kann bytevyte Fehler machen. Benutzern wird empfohlen, alle Informationen unabhängig zu überprüfen. Wir übernehmen keine Haftung für Fehler oder Auslassungen.
Sources
Task-Seeded Synthetic Q&A Generation for Nemotron Pretraining
Related Articles
- NVIDIA enthüllt Physical AI Agent Skills zur Beschleunigung des Trainings autonomer Systeme
- NVIDIA und HuggingFace nutzen synthetische Personas zur Lokalisierung von Korean AI agents
- NVIDIA enthüllt Nemotron-Labs Diffusion für parallele Textgenerierung in Hochgeschwindigkeit
✔Human Verified