NVIDIA y Hugging Face impulsan el entrenamiento de LLM con la generación de datos sintéticos basados en tareas
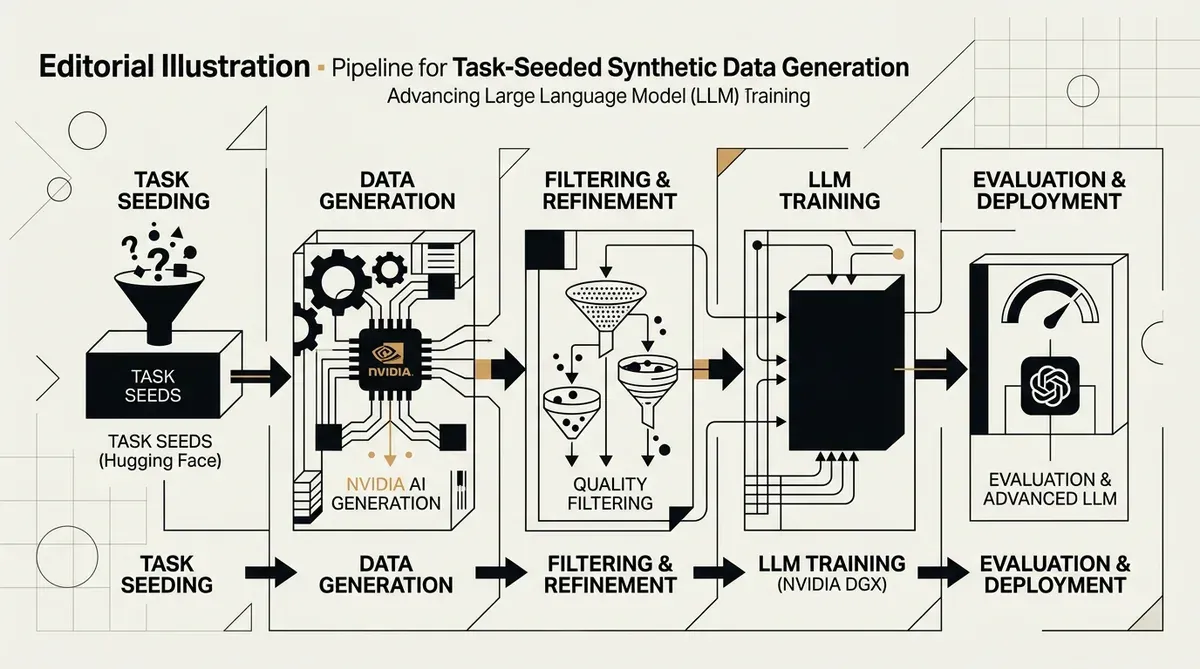
NVIDIA y Hugging Face han presentado una nueva metodología para la task-seeded synthetic data generation, un marco diseñado para mejorar el preentrenamiento de modelos de lenguaje de gran tamaño mediante la creación de conjuntos de entrenamiento estructurados y de alta calidad. Esta investigación colaborativa aborda la creciente escasez de datos generados por humanos utilizando capacidades de tareas existentes como semillas para producir pares de preguntas y respuestas sintéticas complejas. El sistema pretende ir más allá de la simple replicación de datos, centrándose en cambio en el aprendizaje por transferencia para potenciar el rendimiento del modelo en diversos dominios.
El proceso de task-seeded synthetic data generation sigue un flujo de trabajo de cinco etapas para garantizar la calidad y utilidad de los resultados. Este flujo comienza con la recopilación de semillas, seguida de la normalización de registros y la generación de ejemplos. Las etapas finales incluyen el enriquecimiento de respuestas, donde se añaden trazas de razonamiento a los datos, y una fase de filtrado para eliminar entradas de baja calidad. Al utilizar 70 tareas y 700 subtareas del lm-eval-harness como semillas, los investigadores han creado una base diversa para generar contenido sintético que incluye tanto contexto como pasos lógicos.
Impacto estratégico en el escalado de modelos
La eficacia de este enfoque se probó utilizando el modelo Nemotron-3 Nano en un experimento de continuación de 100B de tokens. NVIDIA informó que los datos sintéticos estructurados mejoraron el rendimiento del modelo incluso en áreas que no formaban parte de las tareas semilla originales. Esto sugiere que el método es eficaz para mejoras de capacidad general en lugar de simplemente memorizar conjuntos de datos específicos. Para los líderes empresariales, esto representa un cambio en la forma en que los modelos de frontera pueden escalarse eficientemente sin depender únicamente de datos curados por humanos, cada vez más costosos o escasos.
Al enriquecer los datos sintéticos con trazas de razonamiento, el marco proporciona a los modelos los pasos lógicos detrás de una respuesta, lo cual es un factor clave en el desarrollo de capacidades de razonamiento avanzado. Este avance es particularmente relevante para las organizaciones que construyen modelos especializados donde los datos de alta calidad específicos de un dominio son limitados. La colaboración entre NVIDIA y Hugging Face destaca una tendencia hacia flujos de trabajo de datos sintéticos más sofisticados que priorizan la integridad estructural y la profundidad lógica sobre el volumen puro.
A partir de junio de 2026, la integración de tales técnicas de datos sintéticos se está convirtiendo en una parte estándar del ciclo de vida del desarrollo de IA. La capacidad de generar material de entrenamiento de alta fidelidad a partir de un conjunto limitado de semillas de capacidad permite mejoras de modelos más específicas. NVIDIA y Hugging Face han puesto los detalles técnicos de este análisis profundo a disposición de la comunidad de investigación, señalando un impulso para una adopción más amplia de la generación de datos sintéticos estructurados en la industria.
Aunque nos esforzamos por la precisión, bytevyte puede cometer errores. Se aconseja a los usuarios verificar toda la información de forma independiente. No aceptamos ninguna responsabilidad por errores u omisiones.
Sources
Task-Seeded Synthetic Q&A Generation for Nemotron Pretraining
Related Articles
- NVIDIA presenta physical AI agent skills para acelerar el entrenamiento de sistemas autónomos
- NVIDIA y HuggingFace utilizan personas sintéticas para localizar Korean AI agents
- NVIDIA presenta las AI factories para impulsar la próxima generación de agentes autónomos
✔Human Verified