Google e NVIDIA lançam DiffusionGemma para oferecer geração de texto paralela 4x mais rápida
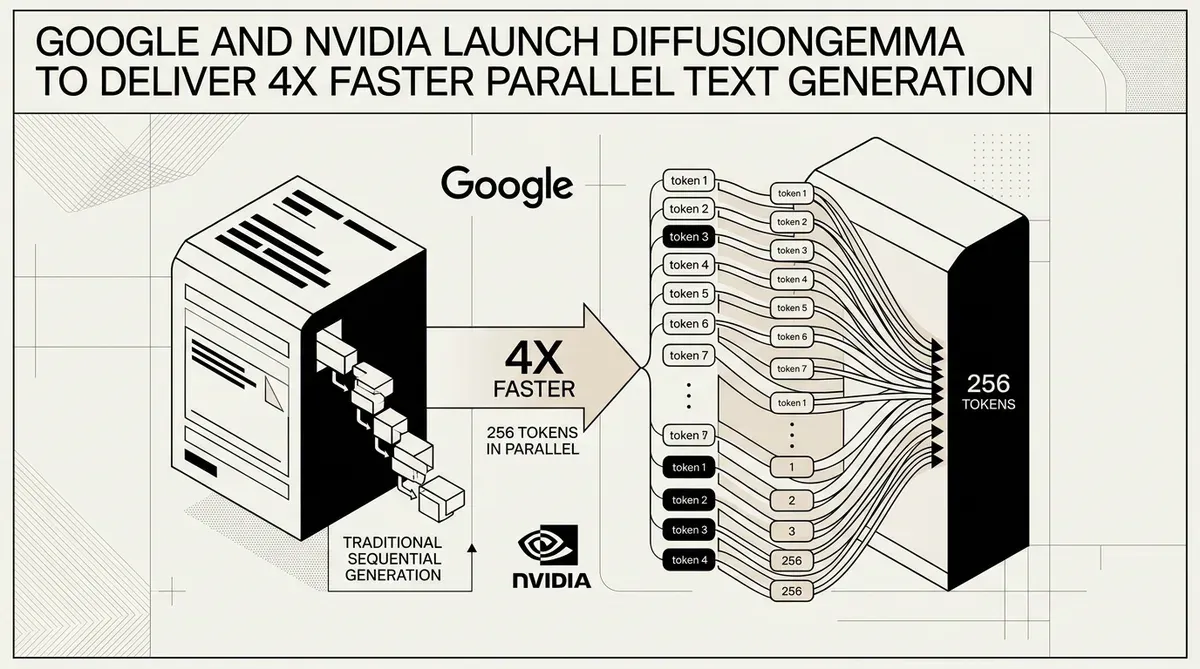
Google e NVIDIA revelaram o DiffusionGemma, um modelo aberto experimental que utiliza uma arquitetura inovadora baseada em difusão para acelerar a geração de texto em até quatro vezes em comparação com os métodos autorregressivos tradicionais. Lançado em 10 de junho de 2026, o modelo desloca o principal gargalo da inferência de grandes modelos de linguagem (LLM) da largura de banda de memória para o poder bruto de processamento (compute). Essa mudança arquitetônica permite que o DiffusionGemma gere 256 tokens em paralelo durante uma única passagem (forward pass), atingindo velocidades de mais de 1.000 tokens por segundo em hardware NVIDIA H100.
O lançamento aborda uma limitação fundamental nos sistemas de IA atuais, onde os tokens são normalmente previstos um por um. Ao integrar uma cabeça de difusão especializada na base da família Gemma 4, o Google DeepMind criou um sistema capaz de geração baseada em blocos. Essa abordagem é particularmente eficaz para tarefas não lineares, como preenchimento de código (code infilling) e edição de documentos complexos, onde a atenção bidirecional oferece uma vantagem de desempenho sobre o processamento padrão da esquerda para a direita.
Especificações Técnicas e Desempenho
O DiffusionGemma é construído sobre uma arquitetura Mixture of Experts (MoE) de 26B, embora utilize apenas 3,8B de parâmetros ativos durante a inferência para manter a eficiência. O modelo está disponível sob uma licença de pesos abertos Apache 2.0, tornando-o acessível para aplicações empresariais e de pesquisa. Para implantações locais, o requisito de VRAM fica em aproximadamente 18GB ao usar quantização, permitindo que ele seja executado em hardware de consumo de ponta.
A NVIDIA forneceu otimização de dia zero para o modelo, garantindo que ele aproveite os Tensor Cores para a matemática paralela densa exigida pelo processo de difusão. Os benchmarks de desempenho compartilhados pelas empresas indicam as seguintes velocidades de saída:
- NVIDIA H100: 1.000+ tokens por segundo.
- NVIDIA RTX 5090: 700+ tokens por segundo.
O modelo também suporta kernels NVFP4 nas arquiteturas Blackwell e Hopper, reduzindo ainda mais a sobrecarga computacional para aplicações em tempo real.
Implicações Estratégicas para IA Corporativa
A introdução do DiffusionGemma sinaliza uma mudança em direção a loops de agentes de baixa latência e assistentes locais altamente interativos. Para os tomadores de decisão, a capacidade de gerar texto nessas velocidades sem depender de uma largura de banda de memória massiva baseada em nuvem abre novas possibilidades para computação de borda (edge computing) e processamento de dados privados. A natureza paralela do modelo o torna um forte candidato para fluxos de trabalho que exigem iteração rápida, como geração de código em tempo real ou refatoração automatizada de conteúdo.
Ao mover o gargalo para o processamento, Google e NVIDIA estão alinhando a arquitetura do modelo com os pontos fortes do hardware de GPU moderno. Esse desenvolvimento sugere que o escalonamento futuro de LLMs pode se concentrar tanto em técnicas de geração paralela quanto na contagem de parâmetros. Os desenvolvedores já podem acessar o modelo por meio de plataformas como Hugging Face Transformers, vLLM e Unsloth para começar a integrar esses recursos de alta velocidade em seus stacks de IA existentes.
Embora nos esforcemos pela precisão, o bytevyte pode cometer erros. Os usuários são aconselhados a verificar todas as informações de forma independente. Não aceitamos qualquer responsabilidade por erros ou omissões.
Sources
DiffusionGemma: 4x faster text generation
NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
Related Articles
- NVIDIA revela Nemotron-Labs Diffusion para geração paralela de texto em alta velocidade
- Google acelera inferência de IA com drafters Gemma 4 Multi-Token Prediction
- NVIDIA e Hugging Face Avançam no Treinamento de LLM com Task-Seeded Synthetic Data Generation
✔Human Verified