Google e NVIDIA Lanciano DiffusionGemma per una Generazione di Testo Parallela 4 Volte più Veloce
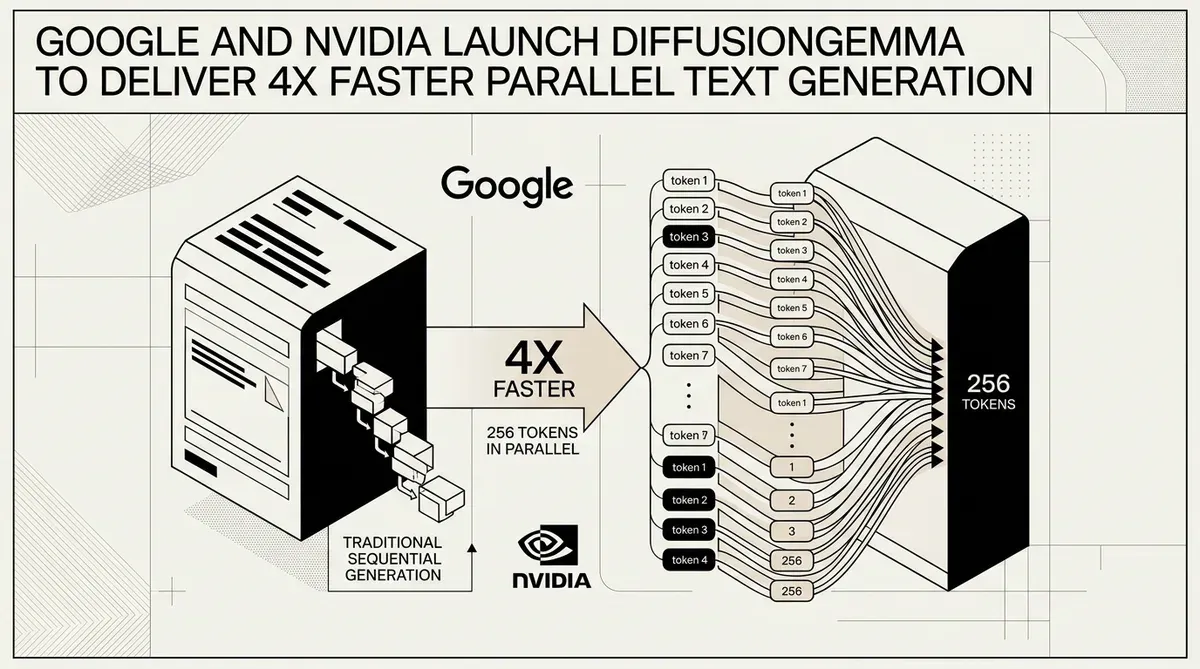
Google e NVIDIA hanno svelato DiffusionGemma, un modello open sperimentale che utilizza una nuova architettura basata sulla diffusione per accelerare la generazione di testo fino a quattro volte rispetto ai tradizionali metodi autoregressivi. Rilasciato il 10 giugno 2026, il modello sposta il principale collo di bottiglia dell'inferenza dei Large Language Model (LLM) dalla larghezza di banda della memoria alla pura potenza di calcolo. Questo cambiamento architetturale consente a DiffusionGemma di generare 256 token in parallelo durante un singolo passaggio in avanti, raggiungendo velocità superiori a 1.000 token al secondo su hardware NVIDIA H100.
Il rilascio affronta una limitazione fondamentale degli attuali sistemi di IA in cui i token vengono tipicamente previsti uno alla volta. Integrando una testa di diffusione specializzata sulla base della famiglia Gemma 4, Google DeepMind ha creato un sistema capace di generazione basata su blocchi. Questo approccio è particolarmente efficace per compiti non lineari come il code infilling e l'editing di documenti complessi, dove l'attenzione bidirezionale offre un vantaggio prestazionale rispetto all'elaborazione standard da sinistra a destra.
Specifiche Tecniche e Prestazioni
DiffusionGemma è costruito su un'architettura Mixture of Experts (MoE) da 26B, sebbene utilizzi solo 3,8B di parametri attivi durante l'inferenza per mantenere l'efficienza. Il modello è disponibile con licenza open-weight Apache 2.0, rendendolo accessibile per applicazioni aziendali e di ricerca. Per le implementazioni locali, il requisito di VRAM si attesta a circa 18GB quando si utilizza la quantizzazione, consentendone l'esecuzione su hardware consumer di fascia alta.
NVIDIA ha fornito un'ottimizzazione day-zero per il modello, assicurando che sfrutti i Tensor Core per la complessa matematica parallela richiesta dal processo di diffusione. I benchmark prestazionali condivisi dalle aziende indicano le seguenti velocità di output:
- NVIDIA H100: oltre 1.000 token al secondo.
- NVIDIA RTX 5090: oltre 700 token al secondo.
Il modello supporta anche i kernel NVFP4 sulle architetture Blackwell e Hopper, riducendo ulteriormente il carico computazionale per le applicazioni in tempo reale.
Implicazioni Strategiche per l'IA Aziendale
L'introduzione di DiffusionGemma segna un passaggio verso cicli agentici a bassa latenza e assistenti locali altamente interattivi. Per i decisori, la capacità di generare testo a queste velocità senza fare affidamento su massicce larghezze di banda di memoria basate su cloud apre nuove possibilità per l'edge computing e l'elaborazione di dati privati. La natura parallela del modello lo rende un candidato ideale per workflow che richiedono iterazioni rapide, come la generazione di codice in tempo reale o il refactoring automatizzato dei contenuti.
Spostando il collo di bottiglia sul calcolo, Google e NVIDIA stanno allineando l'architettura dei modelli con i punti di forza dell'hardware GPU moderno. Questo sviluppo suggerisce che il futuro scaling degli LLM potrebbe concentrarsi tanto sulle tecniche di generazione parallela quanto sul numero di parametri. Gli sviluppatori possono già accedere al modello tramite piattaforme come Hugging Face Transformers, vLLM e Unsloth per iniziare a integrare queste capacità ad alta velocità nei loro stack di IA esistenti.
Sebbene ci sforziamo per l'accuratezza, bytevyte può commettere errori. Si consiglia agli utenti di verificare tutte le informazioni in modo indipendente. Non accettiamo alcuna responsabilità per errori o omissioni.
Sources
DiffusionGemma: 4x faster text generation
NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
Related Articles
- NVIDIA presenta Nemotron-Labs Diffusion per la generazione di testo parallela ad alta velocità
- Google accelera l'inferenza AI con i drafter Gemma 4 Multi-Token Prediction
- NVIDIA presenta Nemotron 3 Nano Omni per ottimizzare i flussi di lavoro AI multimodali
✔Human Verified