Google y NVIDIA lanzan DiffusionGemma para ofrecer una generación de texto en paralelo 4 veces más rápida
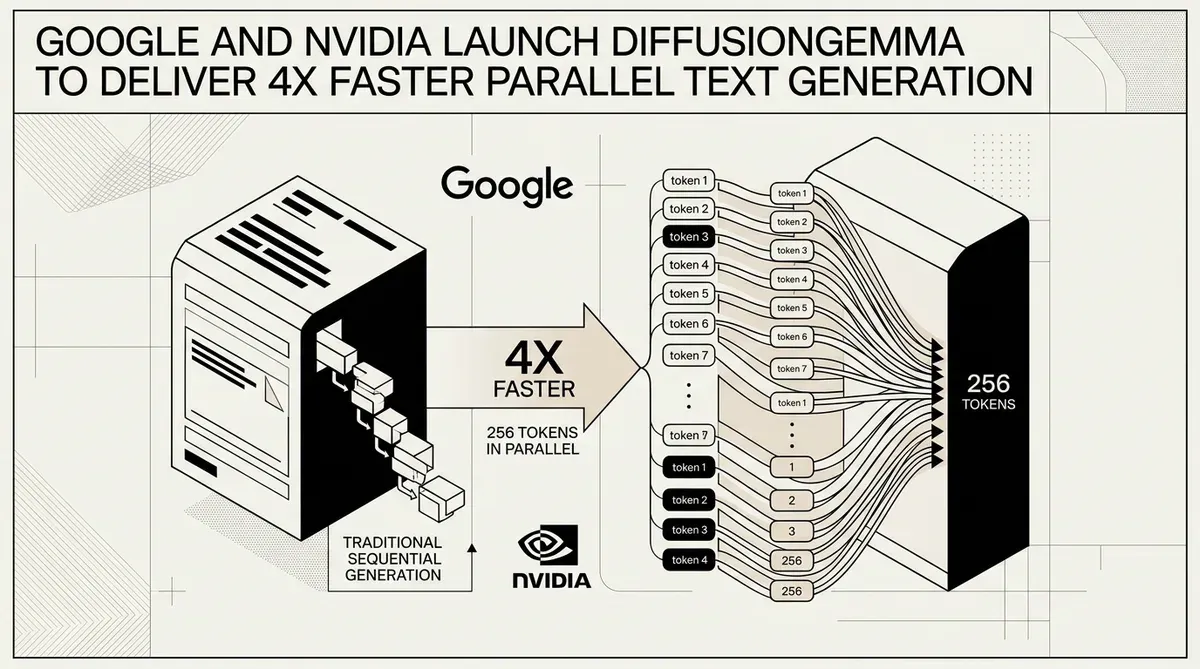
Google y NVIDIA han presentado DiffusionGemma, un modelo abierto experimental que utiliza una novedosa arquitectura basada en difusión para acelerar la generación de texto hasta cuatro veces en comparación con los métodos autorregresivos tradicionales. Lanzado el 10 de junio de 2026, el modelo traslada el principal cuello de botella de la inferencia de los grandes modelos de lenguaje (LLM) del ancho de banda de memoria a la potencia de cómputo bruta. Este cambio arquitectónico permite a DiffusionGemma generar 256 tokens en paralelo durante una sola pasada hacia adelante, alcanzando velocidades de más de 1.000 tokens por segundo en hardware NVIDIA H100.
El lanzamiento aborda una limitación fundamental en los sistemas de IA actuales, donde los tokens se predicen típicamente uno por uno. Al integrar un cabezal de difusión especializado en la base de la familia Gemma 4, Google DeepMind ha creado un sistema capaz de realizar una generación basada en bloques. Este enfoque es particularmente eficaz para tareas no lineales, como el relleno de código (code infilling) y la edición de documentos complejos, donde la atención bidireccional proporciona una ventaja de rendimiento sobre el procesamiento estándar de izquierda a derecha.
Especificaciones técnicas y rendimiento
DiffusionGemma está construido sobre una arquitectura Mixture of Experts (MoE) de 26B, aunque solo utiliza 3.8B de parámetros activos durante la inferencia para mantener la eficiencia. El modelo está disponible bajo una licencia de pesos abiertos Apache 2.0, lo que lo hace accesible para aplicaciones empresariales y de investigación. Para despliegues locales, el requisito de VRAM se sitúa en aproximadamente 18GB cuando se utiliza cuantización, lo que permite que se ejecute en hardware de consumo de gama alta.
NVIDIA ha proporcionado optimización desde el primer día para el modelo, asegurando que aproveche los Tensor Cores para las matemáticas densas en paralelo requeridas por el proceso de difusión. Los puntos de referencia de rendimiento compartidos por las empresas indican las siguientes velocidades de salida:
- NVIDIA H100: más de 1.000 tokens por segundo.
- NVIDIA RTX 5090: más de 700 tokens por segundo.
El modelo también es compatible con kernels NVFP4 en las arquitecturas Blackwell y Hopper, lo que reduce aún más la carga computacional para aplicaciones en tiempo real.
Implicaciones estratégicas para la IA empresarial
La introducción de DiffusionGemma señala un cambio hacia bucles agénticos de baja latencia y asistentes locales altamente interactivos. Para los responsables de la toma de decisiones, la capacidad de generar texto a estas velocidades sin depender de un ancho de banda de memoria masivo basado en la nube abre nuevas posibilidades para la computación en el borde (edge computing) y el procesamiento de datos privados. La naturaleza paralela del modelo lo convierte en un fuerte candidato para flujos de trabajo que requieren una iteración rápida, como la generación de código en tiempo real o la refactorización automatizada de contenido.
Al trasladar el cuello de botella al cómputo, Google y NVIDIA están alineando la arquitectura del modelo con las fortalezas del hardware GPU moderno. Este desarrollo sugiere que el escalado futuro de los LLM podría centrarse tanto en las técnicas de generación paralela como en el recuento de parámetros. Los desarrolladores ya pueden acceder al modelo a través de plataformas como Hugging Face Transformers, vLLM y Unsloth para comenzar a integrar estas capacidades de alta velocidad en sus infraestructuras de IA existentes.
Aunque nos esforzamos por la exactitud, bytevyte puede cometer errores. Se aconseja a los usuarios verificar toda la información de forma independiente. No aceptamos ninguna responsabilidad por errores u omisiones.
Sources
DiffusionGemma: 4x faster text generation
NVIDIA Accelerates Google DeepMind’s DiffusionGemma for Local AI
Related Articles
- NVIDIA presenta Nemotron-Labs Diffusion para la generación de texto en paralelo a alta velocidad
- Google acelera la inferencia de IA con los drafters de Gemma 4 multi-token prediction
- NVIDIA y Hugging Face impulsan el entrenamiento de LLM con la generación de datos sintéticos basados en tareas
✔Human Verified