ai-beats-es
|
NVIDIA presenta Nemotron-Labs Diffusion para la generación de texto en paralelo a alta velocidad
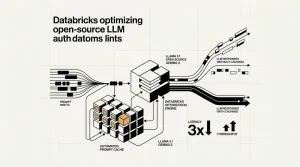
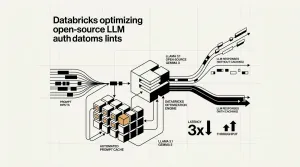
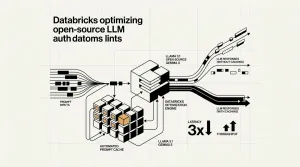
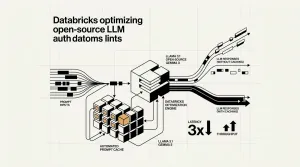
NVIDIA lanza Nemotron-Labs Diffusion, modelos que usan generación de tokens en paralelo para alcanzar 865 tokens/seg en hardware Blackwell B200.